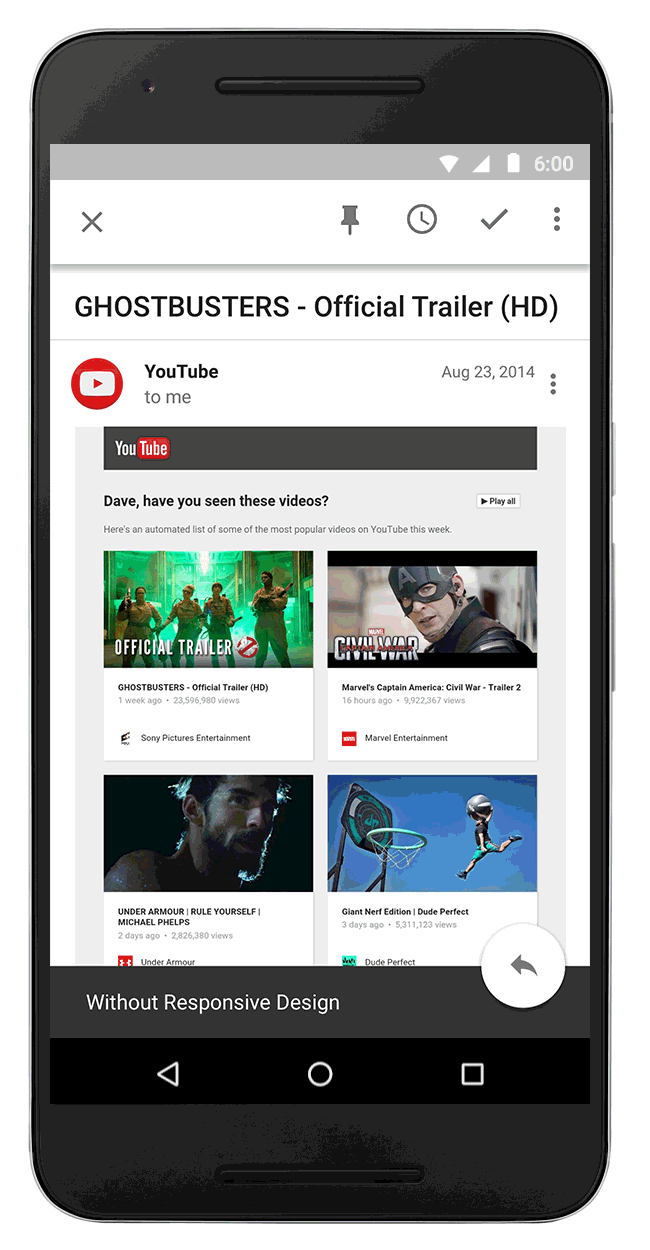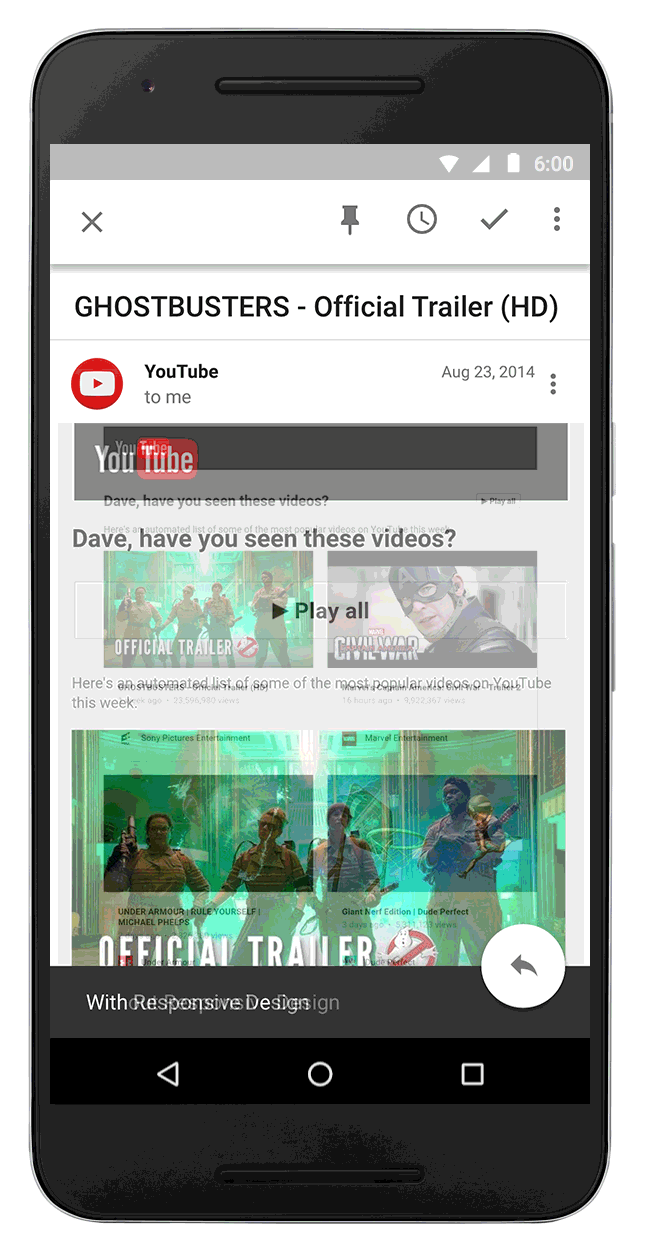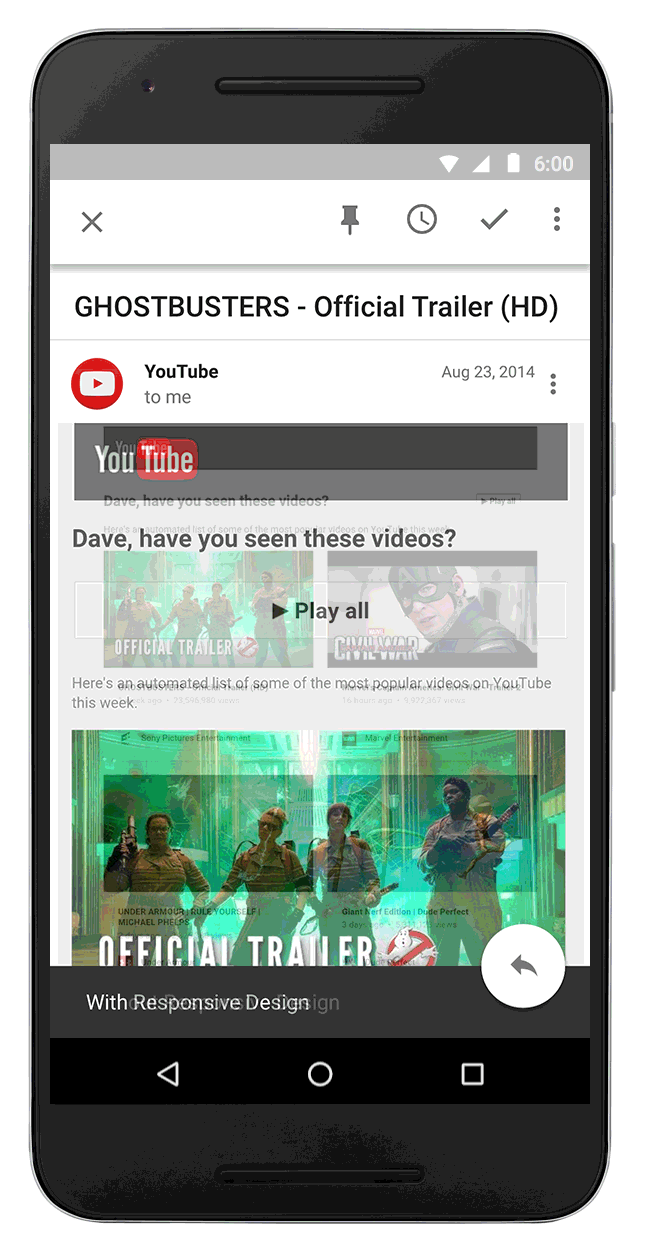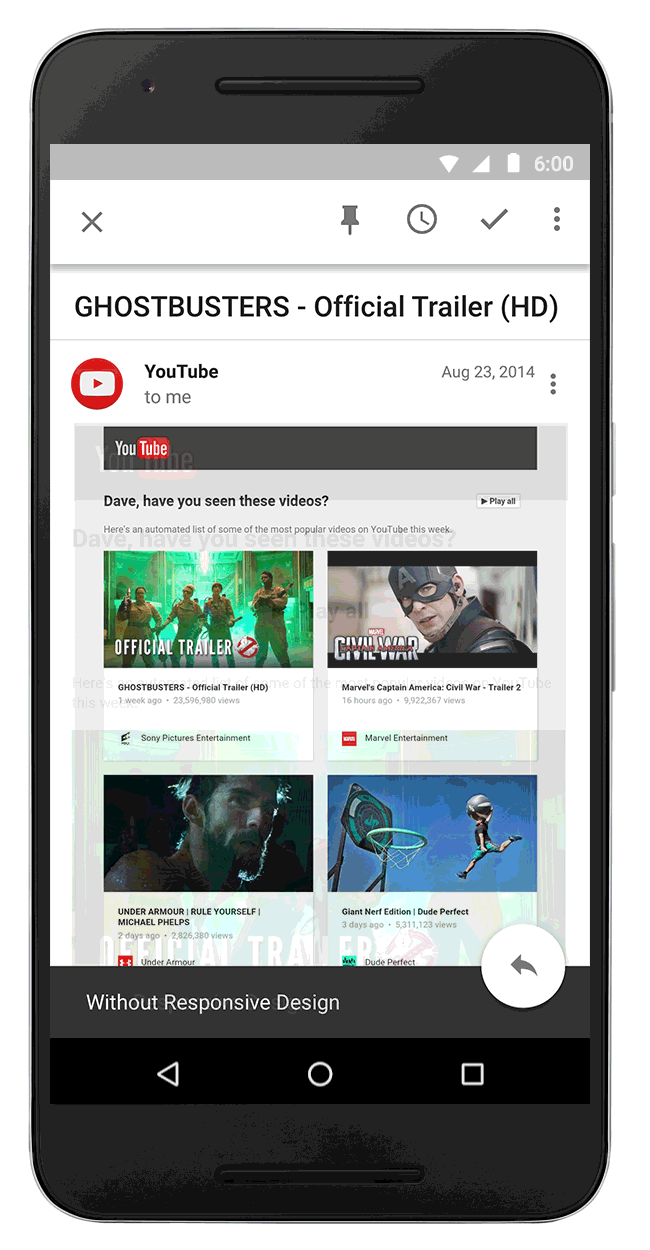
When I started at Google 13 years ago, I was an ad tech engineer building products based on the idea that an online ad is only effective if it leads to a click and a purchase. It sounded simple at the time, but it’s revolutionized the way brands connect with consumers.
Today, our industry is adjusting to another revolution, and it’s all thanks to the tiny device we carry with us everywhere we go – our phones. Throughout the day, when we want to go somewhere, watch something, or buy something, we reach for our mobile devices for help, whether it’s to find the best hotel deal or buy the perfect car. And billions of times a day, we find what we want on Google, YouTube, Maps, and Play. This morning at dmexco, a digital conference in Cologne, Germany, I announced two ad innovations that will help you be there in those moments, connecting the right consumers with what they want, when they want it.
Go beyond the install and find your most valuable customers
Apps are ubiquitous with mobile and are an increasingly important touchpoint for consumers. To date, AdWords has delivered more than 3 billion app downloads to developers and advertisers.
1 And I meet with many of you from around the world to learn about the creative ways you’re connecting with your users – it’s the best part of my job. One insight I keep hearing is that users who engage with your app are the users that matter the most to your business.
It’s not just about driving installs, it’s about delivering valuable actions within your apps – whether it’s reaching a specific level in a game or completing a purchase. We set out to solve this challenge.
At dmexco this morning, I announced
the next generation of Universal App Campaigns, available globally to all advertisers. Across Google Search, Play, YouTube, and the millions of sites and apps in the Google Display Network, Universal App Campaigns can now help you find the customers that matter most to you, based on your defined business goals.
trivago, a popular hotel search app, was one of the first to test this new version of Universal App Campaigns. The brand cares deeply about helping travelers find the perfect hotel room and knows that users who tap on a deal are more likely to take the next step: book a stay.

|
| Example of the user journey from install to viewing a deal on a hotel room |
Like trivago, you get to choose the in-app activity you want to optimize for, whether that’s tapping into a deal or reaching level 10, and can use third-party measurement partners or Google’s app measurement solutions like Firebase Analytics to measure those activities. Once your in-app activities are defined within AdWords, you’ve plugged in your analytics solution, and set your cost-per-install, Google will put our machine learning algorithm to work. Universal App Campaigns evaluate countless signals in real time to continuously refine your ads so you can reach your most valuable users at the right price across Google’s largest properties. As people start to engage with your ads, we learn where you’re finding the highest value users. For example, we may learn that the users who tap into the most hotel deals are those who watch travel vlogs on YouTube. So, we'll show more of your ads on those types of YouTube channels.
For trivago, Universal App Campaigns was able to find users who were more likely to click on hotel deals in app to book a room. As a result, the travel brand acquired customers who were 20% more valuable to its business across both Android and iOS.
This is a major shift in how Google can help you grow your app business. We’re listening, and we’re no longer just focusing on the install. Our goal with Universal App Campaigns is to deliver user engagement and value for the apps you worked so hard to build.
Turn consideration into action with TrueView for action
The mobile revolution hasn’t just changed how we search or interact with apps, it's also changed the way we interact with almost every kind of media. Nowhere is this more evident than the way people watch video. We see this every day on YouTube.
In a recent study, we found that 47% of U.S. adults aged 18 to 54 say YouTube helps them at least once a month when making a decision about buying something – that’s an estimated 70 million people going to YouTube every month for help with a purchase.
2 These intent-rich moments are opportunities for brands to connect with consumers when it matters, so we took on the challenge of making it easier for consumers to move from consideration to purchase.
Over the last few years, we’ve evolved our TrueView format to change the way video delivers value for performance marketers. TrueView for app promotion and TrueView for shopping make it incredibly easy for brands to drive downloads and purchases directly from YouTube. But what about brands with other types of conversions, like requesting a quote, booking a hotel, signing up for a newsletter, or scheduling a test drive?
Today I’m excited to introduce
TrueView for action: a new format that encourages users to take any online action that’s meaningful for your business.

|
| TrueView for action example |
TrueView for action makes your video ad more actionable by displaying a tailored call-to-action during and after your video. This call-to-action can be adapted to your specific use case, like “Get a quote,” “Book now” or “Sign up.” Since this is an easy add-on to your video, you can drive performance on top of all the benefits of showing your video to an engaged audience. This is especially advantageous for brands that offer products or services with high consideration, like financial services, automotive, or travel. TrueView for action can help you move your customers along the path to purchase by encouraging actions like scheduling an appointment or requesting more information. We’re excited to start testing this new format with advertisers throughout the rest of this year.
As consumers live their lives in a mobile-first world, it’s increasingly important for brands to build transformational mobile experiences. We know it’s not always easy, and Google is here to help. It’s been so inspiring to see so many of you deliver extraordinary experiences for your customers, and I think dmexco embodies this shared passion and innovative spirit for connecting brands with consumers. I look forward to meeting with more of you and continuing along this amazing journey.
Posted by Sridhar Ramaswamy, Senior Vice President, Ads and Commerce
1. Google Internal Data, Global
2. Google / Ipsos Connect, YouTube Sports Viewers Survey, U.S., March 2016 (n=1500, 18-54 year olds)