New mobile apps for Docs and Sheets — work offline and on the go
April 30th, 2014 | by Jane Smith | published in Google Apps, Google Docs
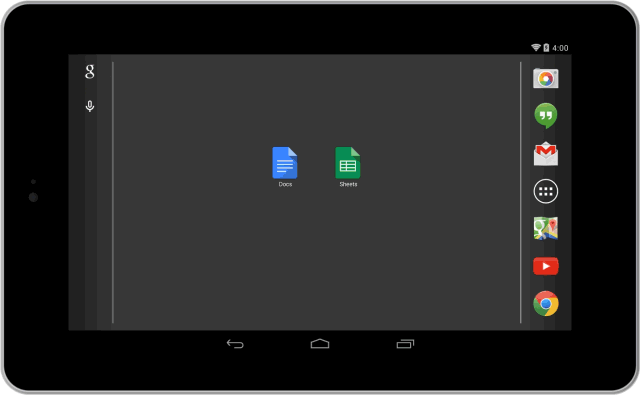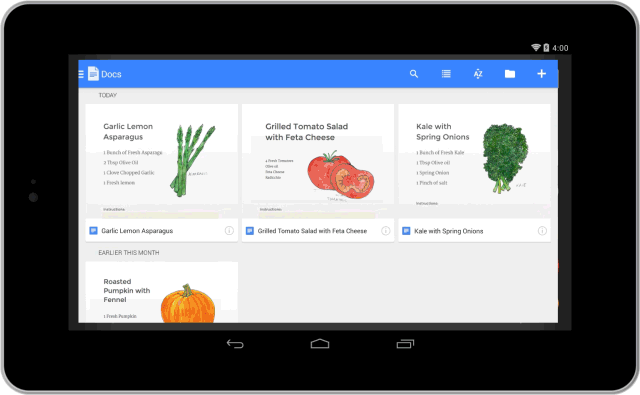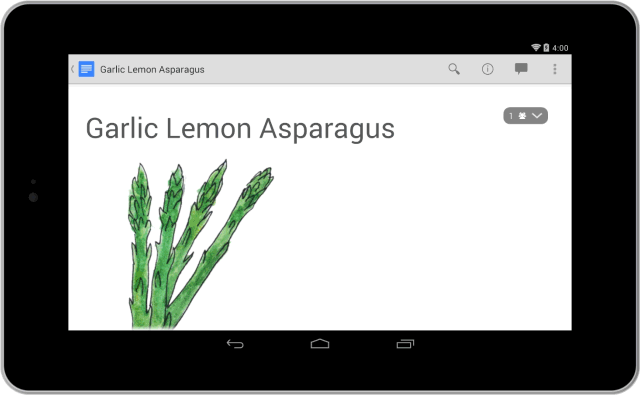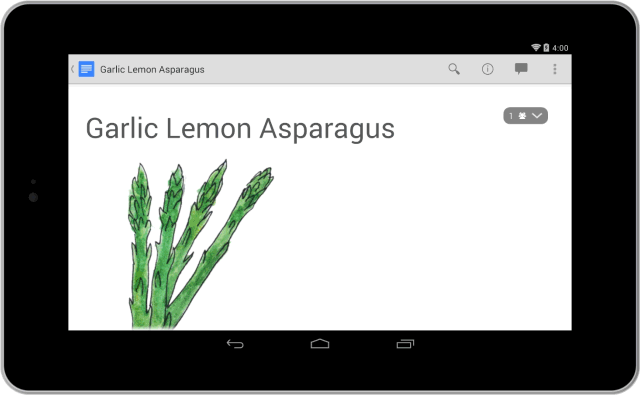
Starting today, you can download new, standalone mobile apps for Docs and Sheets—with Slides coming soon.
When you open the new apps, you’ll see your most recently edited files, which means less time searching and scrolling.
The apps also come with offline support built in, so you can easily view, edit and create files without an Internet connection.
You can get the apps on Google Play [Docs] [Sheets] and in the App Store [Docs] [Sheets]. If you don’t have time now, over the next few days you’ll be prompted to download the apps when you go to edit or create a document or spreadsheet in your Drive app. You will still be able to use the Drive app to view and organize all of your documents, spreadsheets, presentations, photos and more.
Release Track:
Scheduled release
Editions included:
Google Apps for Business, Education and Government
For more information:
http://googleblog.blogspot.com/2014/04/new-mobile-apps-for-docs-sheets-and.html
When you open the new apps, you’ll see your most recently edited files, which means less time searching and scrolling.
The apps also come with offline support built in, so you can easily view, edit and create files without an Internet connection.
You can get the apps on Google Play [Docs] [Sheets] and in the App Store [Docs] [Sheets]. If you don’t have time now, over the next few days you’ll be prompted to download the apps when you go to edit or create a document or spreadsheet in your Drive app. You will still be able to use the Drive app to view and organize all of your documents, spreadsheets, presentations, photos and more.
Release Track:
Scheduled release
Editions included:
Google Apps for Business, Education and Government
For more information:
http://googleblog.blogspot.com/2014/04/new-mobile-apps-for-docs-sheets-and.html
whatsnew.googleapps.com
Get these product update alerts by email
Subscribe to the RSS feed of these updates