3D graphics are a fundamental part of many applications, including gaming, design and data visualization. As graphics processors and creation tools continue to improve, larger and more complex 3D models will become commonplace and help fuel new applications in immersive virtual reality (VR) and augmented reality (AR). Because of this increased model complexity, storage and bandwidth requirements are forced to keep pace with the explosion of 3D data.
The Chrome Media team has created Draco, an open source compression library to improve the storage and transmission of 3D graphics. Draco can be used to compress meshes and point-cloud data. It also supports compressing points, connectivity information, texture coordinates, color information, normals and any other generic attributes associated with geometry.
With Draco, applications using 3D graphics can be significantly smaller without compromising visual fidelity. For users this means apps can now be downloaded faster, 3D graphics in the browser can load quicker, and VR and AR scenes can now be transmitted with a fraction of the bandwidth, rendered quickly and look fantastic.
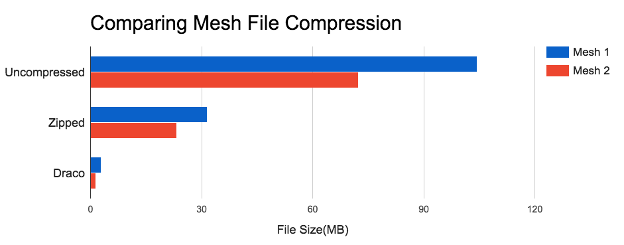
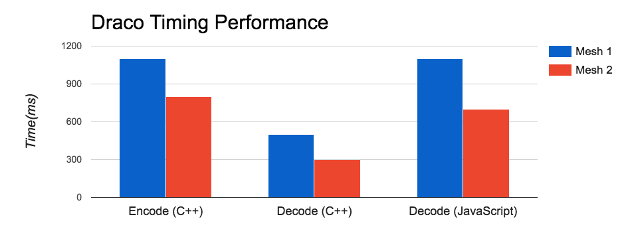
Sample Draco compression ratios and encode/decode performance*
Transmitting 3D graphics for web-based applications is significantly faster using Draco’s JavaScript decoder, which can be tied to a 3D web viewer. The following video shows how efficient transmitting and decoding 3D objects in the browser can be - even over poor network connections.
Public domain Discobolus model from SMK National Gallery of Denmark.
Video and audio compression have shaped the internet over the past 10 years with streaming video and music on demand. With the emergence of VR and AR, on the web and on mobile (and the increasing proliferation of sensors like LIDAR) we will soon be swimming in a sea of geometric data. Compression technologies, like Draco, will play a critical role in ensuring these experiences are fast and accessible to anyone with an internet connection. More exciting developments are in store for Draco, including support for creating multiple levels of detail from a single model to further improve the speed of loading meshes.
We look forward to seeing what people do with Draco now that it's open source. Check out the code on GitHub and let us know what you think. Also available is a JavaScript decoder with examples on how to incorporate Draco into the three.js 3D viewer.
By Jamieson Brettle and Frank Galligan, Chrome Media Team
* Specifications: Tests ran with textures and positions quantized at 14-bit precision, normal vectors at 7-bit precision. Ran on a single-core of a 2013 MacBook Pro. JavaScript decoded using Chrome 54 on Mac OS X.
Calling all developers in Europe, the Middle East and Africa: our programming competitionHash Codeis back for its fourth year of challenging programmers to solve a real Google engineering problem. Think you couldoptimize the layout of a Google Data Center? Or how aboutscheduling a fleet of dronesto make deliveries around the world? If you’re up for the challenge, sign up to compete today atg.co/hashcode.
Hash Code 2017 kicks off on 23rd February with the Online Qualification Round. The top 50 teams from this round will then be invited toGoogle Paris, in the City of Light, to battle it out for the coveted title of Hash Code 2017 Champion.
52 teams from 22 countries competed side-by-side during theHash Code 2016 Final Roundat Google Paris
To make things even more exciting, students and professionals across the region are signing up to host Hash Codehubswhere local teams can come together to compete for the Online Qualification Round. So far, more than 250 hubs are being organized across Europe, the Middle East and Africa. Participating from a hub is a great way to meet new people and add a little extra fun and competition to the contest.Don’t see a hub near you? You can stillsign up to host a hubin your university, office or city on our website.
Whether you’ve just started coding or you’re a programming competition aficionado, Hash Code is a great chance to flex your programming muscles, get a glimpse into software engineering at Google and have some fun. Take a look atprevious Hash Code problem statementsto see the engineering challenges participants have tackled in the past.
Teams compete in the 2016 Online Qualification Round from a Hash Codehub
We can’t reveal this year’s problem statements, but we will have some other fun announcements leading up to the Online Qualification Round. Keep in touch with Hash Code by joining ourGoogle+ communityandFacebook event.
Are you up for the challenge? Sign up today atg.co/hashcodeand we’ll see you online on 23rd February!
Lindsay Taub
University Programs Team
Upcoming changes to the Google Play Private Channel
We are excited to announce a few upcoming changes to the Google Play Private Channel, a feature which allows G Suite admins to distribute private (custom) Android apps to their users via the Play Store app.
With this launch, private apps will be more discoverable and easier for your users to access. Customers using private apps will also be able to whitelist these apps for work profiles and company-owned devices in a more streamlined manner by using an Enterprise Mobility Management (EMM) provider.
Making private apps more discoverable and easier for your users to access
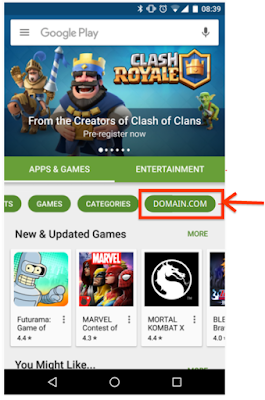
Previously, private apps were located in your company’s Private Channel: in the Play Store Android app under the tab [your organization’s name], which is the last category within the Play app.
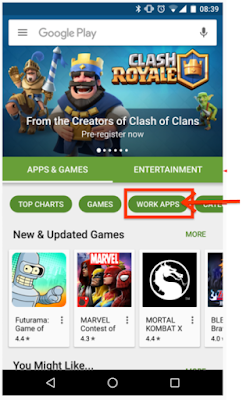
In order to make these apps easier for users to access, private apps will be relocated to the “Work Apps” tab within the Play app, the third category, which will also contain any managed applications if your organization is using an EMM provider, such as Google Mobile Management.
Making “Work Apps” richer with private apps and managed Google Play (formerly Play for Work) for new customers
Our vision for “Work Apps” within Google Play is for it to become the single destination for corporate users to find all of the applications they need. G Suite admins will be able to offer a curated set of both public and private applications specific to your enterprise for your employees.
You will also no longer need to manage different access controls for your employees; controls for both private and public applications within managed Play will be consolidated, simplifying the whitelisting process for mobile applications.
As part of this simplified whitelisting process, customers who currently are not using Google Play Private Channel, and want to deploy private apps for the first time, must enroll with an EMM, such as Google Mobile Management, and must enroll with managed Google Play. This will allow you to make private applications available in work profiles and on company-owned devices, as you currently can do with managed public applications. Customers currently using Google Play Private Channel are not required to use an EMM and can continue to use private applications as they do today.
We are expecting to launch these changes to Google Play Private Channel on January 31, 2017.
Launch Details Release track:
Launching to both Rapid release and Scheduled release on January 31, 2017
Rollout pace:
Full rollout (1-3 days for feature visibility)
Editions:
Available to all G Suite editions
Impact:
Admins and end users
Action:
Admin action suggested
More Information
Google Play Private Channel applications
Launch release calendar Launch detail categories Get these product update alerts by email Subscribe to the RSS feed of these updates
Posted by Jeff Dean, Google Senior Fellow, on behalf of the entire Google Brain team
The Google Brain team's long-term goal is to create more intelligent software and systems that improve people's lives, which we pursue through both pure and applied research in a variety of different domains. And while this is obviously a long-term goal, we would like to take a step back and look at some of the progress our team has made over the past year, and share what we feel may be in store for 2017.
Research Publications
One important way in which we assess the quality of our research is through publications in top tier international machine learning venues like ICML, NIPS, and ICLR. Last year our team had a total of 27 accepted papers at these venues, covering a wide ranging set of topics including program synthesis, knowledge transfer from one network to another, distributed training of machine learning models, generative models for language, unsupervised learning for robotics, automated theorem proving, better theoretical understanding of neural networks, algorithms for improved reinforcement learning, and many others. We also had numerous other papers accepted at conferences in fields such as natural language processing (ACL, CoNNL), speech (ICASSP), vision (CVPR), robotics (ISER), and computer systems (OSDI). Our group has also submitted 34 papers to the upcoming ICLR 2017, a top venue for cutting-edge deep learning research. You can learn more about our work in our list of papers, here.
Natural Language Understanding
Allowing computers to better understand human language is one key area for our research. In late 2014, three Brain team researchers published a paper on Sequence to Sequence Learning with Neural Networks, and demonstrated that the approach could be used for machine translation. In 2015, we showed that this this approach could also be used for generating captions for images, parsing sentences, and solving computational geometry problems. In 2016, this previous research (plus many enhancements) culminated in Brain team members worked closely with members of the Google Translate team to wholly replace the translation algorithms powering Google Translate with a completely end-to-end learned system (research paper). This new system closed the gap between the old system and human quality translations by up to 85% for some language pairs. A few weeks later, we showed how the system could do “zero-shot translation”, learning to translate between languages for which it had never seen example sentence pairs (research paper). This system is now deployed on the production Google Translate service for a growing number of language pairs, giving our users higher quality translations and allowing people to communicate more effectively across language barriers. Gideon Lewis-Kraus documented this translation effort (along with the history of deep learning and the history of the Google Brain team) in “The Great A.I. Awakening”, an in-depth article that appeared in The NY Times Magazine in December, 2016.
Robotics
Traditional robotics control algorithms are carefully and painstakingly hand-programmed, and therefore embodying robots with new capabilities is often a very laborious process. We believe that having robots automatically learn to acquire new skills through machine learning is a better approach. Last year, we collaborated with researchers at [X] to demonstrate how robotic arms could learn hand-eye coordination, pooling their experiences to teach themselves more quickly (research paper). Our robots made about 800,000 grasping attempts during this research. Later in the year, we explored three possible ways for robots to learn new skills, through reinforcement learning, through their own interaction with objects, and through human demonstrations. We’re continuing to build on this work in our goals for making robots that are able to flexibly and readily learn new tasks and operate in messy, real-world environments. To help other robotics researchers, we have made multiple robotics datasets publicly available.
Healthcare
We are excited by the potential to use machine learning to augment the abilities of doctors and healthcare practitioners. As just one example of the possibilities, in a paper published in the Journal of the American Medical Association (JAMA), we demonstrated that a machine-learning driven system for diagnosing diabetic retinopathy from a retinal image could perform on-par with board-certified ophthalmologists. With more than 400 million people at risk for blindness if early symptoms of diabetic retinopathy go undetected, but too few ophthalmologists to perform the necessary screening in many countries, this technology could help ensure that more people receive the proper screening. We are also doing work in other medical imaging domains, as well as investigating the use of machine learning for other kinds of medical prediction tasks. We believe that machine learning can improve the quality and efficiency of the healthcare experience for doctors and patients, and we’ll have more to say about our work in this area in 2017.
Music and Art Generation
Technology has always helped define how people create and share media — consider the printing press, film or the electric guitar. Last year we started a project called Magenta to explore the intersection of art and machine intelligence, and the potential of using machine learning systems to augment human creativity. Starting with music and image generation and moving to areas like text generation and VR, Magenta is advancing the state-of-the-art in generative models for content creation. We’ve helped to organize a one-day symposium on these topics and supported an art exhibition of machine generated art. We’ve explored a variety of topics in music generation and artistic style transfer, and our jam session demo won the Best Demo Award at NIPS 2016.
AI Safety and Fairness
As we develop more powerful and sophisticated AI systems and deploy them in a wider variety of real-world settings, we want to ensure that these systems are both safe and fair, and we also want to build tools to help humans better understand the output they produce. In the area of AI safety, in a cross-institutional collaboration with researchers at Stanford, Berkeley, and OpenAI, we published a white paper on Concrete Problems in AI Safety (see the blog post here). The paper outlines some specific problems and areas where we believe there is real and foundational research to be done in the area of AI safety. One aspect of safety on which we are making progress is the protection of the privacy of training data, obtaining differential privacy guarantees, most recently via knowledge transfer techniques. In addition to safety, as we start to rely on AI systems to make more complex and sophisticated decisions, we want to ensure that those decisions are fair. In a paper on equality of opportunity in supervised learning (see the blog post here), we showed how to optimally adjust any trained predictor to prevent one particular formal notion of discrimination, and the paper illustrated this with a case study based on FICO credit scores. To make this work more accessible, we also created a visualization to help illustrate and interactively explore the concepts from the paper.
TensorFlow
In November 2015, we open-sourced an initial version of TensorFlow so that the rest of the machine learning community could benefit from it and we could all collaborate to jointly improve it. In 2016, TensorFlow became the most popular machine learning project on GitHub, with over 10,000 commits by more than 570 people. TensorFlow’s repository of models has grown with contributions from the community, and there are also more than 5000 TensorFlow-related repositories listed on GitHub alone! Furthermore, TensorFlow has been widely adopted by well-known research groups and large companies including DeepMind, and applied towards or some unusual applications like finding sea cows Down Under and sorting cucumbers in Japan.
We’ve made numerous performance improvements, added support for distributed training, brought TensorFlow to iOS, Raspberry Pi and Windows, and integrated TensorFlow with widely-used big data infrastructure. We’ve extended TensorBoard, TensorFlow’s visualization system with improved tools for visualizing computation graphs and embeddings. We’ve also made TensorFlow accessible from Go, Rust and Haskell, released state-of-the-art image classification models, Wide and Deep and answered thousands of questions on GitHub, StackOverflow and the TensorFlow mailing list along the way. TensorFlow Serving simplifies the process of serving TensorFlow models in production, and for those working in the cloud, Google Cloud Machine Learning offers TensorFlow as a managed service.
Last November, we celebrated TensorFlow’s one year anniversary as an open-source project, and presented a paper on the computer systems aspects of TensorFlow at OSDI, one of the premier computer systems research conferences. In collaboration with our colleagues in the compiler team at Google we’ve also been hard at work on a backend compiler for TensorFlow called XLA, an alpha version of which was recently added to the open-source release.
Machine Learning Community Involvement
We also strive to educate and mentor people in how to do machine learning and how to conduct research in this field. Last January, Vincent Vanhoucke, one of the research leads in the Brain team, developed and worked with Udacity to make available a free online deep learning course (blog announcement). We also put together TensorFlow Playground, a fun and interactive system to help people better understand and visualize how very simple neural networks learn to accomplish tasks.
In June we welcomed our first class of 27 Google Brain Residents, selected from more than 2200 applicants, and in seven months they have already conducted significantly original research, helping to author 21 research papers. In August, many Brain team members took part in a Google Brain team Reddit AMA (Ask Me Anything) on r/MachineLearning to answer the community’s questions about machine learning and our team. Throughout the year, we also hosted 46 student interns (mostly Ph.D. students) in our group to conduct research and work with our team members.
Spreading Machine Learning within Google
In addition to the public-facing activities outlined above, we have continued to work within Google to spread machine learning expertise and awareness throughout our many product teams, and to ensure that the company as a whole is well positioned to take advantage of any new machine learning research that emerges. As one example, we worked closely with our platforms team to provide specifications and high level goals for Google’s Tensor Processing Unit (TPU), a custom machine learning accelerator ASIC that was discussed at Google I/O. This custom chip provides an order of magnitude improvement for machine learning workloads, and is heavily used throughout our products, including for RankBrain, for the recently launched Neural Machine Translation system, and for the AlphaGo match against Lee Sedol in Korea last March.
All in all, 2016 was an exciting year for the Google Brain team and our many collaborators and colleagues both within and outside of Google, and we look forward to our machine learning research having significant impact in 2017!
Posted by Ryan Hurst and Gary Belvin, Security and Privacy Engineering
Encryption is a foundational technology for the web. We’ve spent a lot of time working through the intricacies of making encrypted apps easy to use and in the process, realized that a generic, secure way to discover a recipient's public keys for addressing messages correctly is important. Not only would such a thing be beneficial across many applications, but nothing like this exists as a generic technology.
A solution would need to reliably scale to internet size while providing a way to establish secure communications through untrusted servers. It became clear that if we combined insights from Certificate Transparency and CONIKS we could build a system with the properties we wanted and more.
The result is Key Transparency, which we’re making available as an open-source prototype today.
Why Key Transparency is useful Existing methods of protecting users against server compromise require users to manually verify recipients’ accounts in-person. This simply hasn’t worked. The PGP web-of-trust for encrypted email is just one example: over 20 years after its invention, most people still can't or won’t use it, including its original author. Messaging apps, file sharing, and software updates also suffer from the same challenge.
One of our goals with Key Transparency was to simplify this process and create infrastructure that allows making it usable by non-experts. The relationship between online personas and public keys should be automatically verifiable and publicly auditable. Users should be able to see all the keys that have been attached to an account, while making any attempt to tamper with the record publicly visible. This also ensures that senders will always use the same keys that account owners are verifying.
Key Transparency is a general-use, transparent directory that makes it easy for developers to create systems of all kinds with independently auditable account data. It can be used in a variety of scenarios where data needs to be encrypted or authenticated. It can be used to make security features that are easy for people to understand while supporting important user needs like account recovery.
Looking ahead
It’s still very early days for Key Transparency. With this first open source release, we’re continuing a conversation with the crypto community and other industry leaders, soliciting feedback, and working toward creating a standard that can help advance security for everyone.
We’d also like to thank our many collaborators during Key Transparency’s multi-year development, including the CONIKS team, Open Whisper Systems, as well as the security engineering teams at Yahoo! and internally at Google.
Our goal is to evolve Key Transparency into an open-source, generic, scalable, and interoperable directory of public keys with an ecosystem of mutually auditing directories. We welcome your apps, input, and contributions to this new technology at KeyTransparency.org.
By using Customer Match and remarketing lists for search ads (RLSA) in AdWords, you can connect with valuable, returning customers. It’s a powerful way to link intent with context as people search on Google.
We’ve published a new guide that covers everything you should consider as you connect a user’s search with what you already know about them. It covers topics such as:
Powering search campaigns with audience insights
Maximizing engagement when applying your lists
Taking full advantage of other AdWords tools that work well with audiences
Learn how to supercharge your search campaigns using what you already know about your users.
Want to stay on top of even more Best Practices? Sign up to receive our monthly newsletter. Posted by Matt Lawson, Director, Performance Ads Marketing
Manage paid orders and payments settings from the Google Play Developer Console
Posted by Suzanne van Tienen, Product Manager, Google Play
Today we are simplifying and improving the merchant experience for developers who have paid apps, in-app purchases, or subscriptions based on the feedback we've heard from the community.
First, we're moving order management from the Google Payments Center to the Google Play Developer Console and adding some improved features. Second, payments settings will now be accessible from the Developer Console in addition to continuing to be available on payments.google.com. The new features come with appropriate access control settings so you can be sure users only have access to the tools they need.
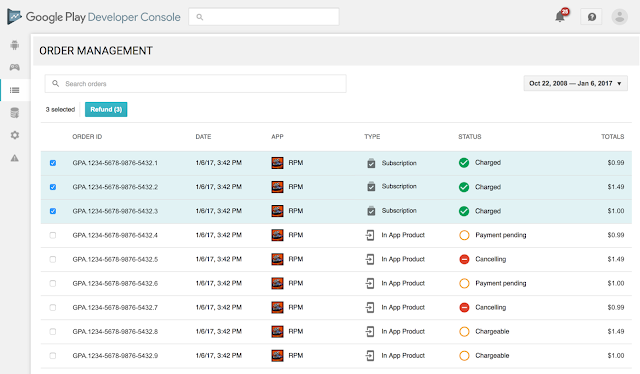
The new order management tab in the Google Play Developer Console You can perform the same tasks in the Developer Console which you previously would have performed in the Google Payments Center. We've also made some improvements:
Bulk refunds: You can now select multiple orders for simultaneous refund, instead of issuing them individually.
Subscription cancellations: You can now refund and revoke subscriptions directly from the order management tab (without going to a separate UI).
Permissions: We've added a new user access permission to the Developer Console called "Manage orders". This permission will allow a user to find orders, issue refunds, and cancel subscriptions. Other features will be read-only for these users and financial reports will be hidden (only users with "View financial reports" can see financial data). Payments settings are restricted to the account owner when accessed from Developer Console.
Order management migration to the Developer Console Order management is now available in the Developer Console. Starting January 23, order management will cease being available in Payments Center. User permissions are not automatically carried over from the Payments Center so, as the account owner, you will need to add all users who need access to refunds and any other order management features to your Developer Console account with the new 'Manage orders' permission by January 22 for them to have continued access.
Here's how you can add new users to your Developer Console account:
Log on to Google Payments Center and review all existing users.
Sign in to your Developer Console and add one or both of the following permissions for all users that need access to Order Management in the Developer Console.
View financial reports: Gives the right to access and view financial reports.
Manage orders: Gives the right to view and refund orders but not to view aggregate financial statistics or download sales & payout reports.
Let your users know about the new location for order management.
How useful did you find this blogpost?
★ ★ ★ ★ ★
CSSI Three-Day Takeover! Day Three: Catching Up With Googler (and former CSSI’er) Kenechi
Today we’re speaking with a CSSI alumni, Kenechi from the class of 2008 (our first iteration of CSSI) who currently works at Google as a Software Engineer. Below, she shares her experience at CSSI and how it put her on the path to Google. Click here if you're ready to apply to CSSI!
Before CSSI, what was your experience with Computer Science? And why did you apply to the program?
I’ve wanted to write software since my first experience with Word 95 when I was little. I took a course on QBASIC in high school but didn’t have an opportunity to take AP Computer Science because it only had 1 offering a year. I took my first full programming course my first semester at CMU. I applied to CSSI because the program’s description sounded cool and I wanted the opportunity to visit Google’s headquarters.
What was your favorite moment during the program?
The final presentations were a great moment for me. It was amazing how much content was covered in two-and-a-half weeks and how much I had gotten to know the other students.
What's the most important lesson you learned?
The most important lesson of CSSI for me was one of validation. After CSSI a career in software engineering became a reality. For two weeks I was able to see what it was like to be at Google; I had the opportunity to meet and learn from dozens of full-time engineers. Even though I was already a CS major at CMU, CSSI formed the foundation for the rest of my career. It was there that I got the confidence and network necessary to succeed as a software engineer.
How did this help you for college going forward?
There was another CMU student in my CSSI class, after CSSI we started a study group. We would meet daily to study and go to office hours together. It really helped having a study group for the rest of time at CMU, especially as the courses got increasingly difficult.
What was your journey to Google?
My journey to Google started with CSSI. I returned as an intern for back to back summers, the first summer in the Engineering Practicum program. After graduating I worked at Microsoft for over two years and then returned to Google.
How did this prepare you for work? And specifically, how did this prepare you to for Google?
The summer after CSSI I had the opportunity to be an EP intern. My internship helped me to experience what day to day software development would be like. CSSI opened the door to that opportunity. CSSI also introduced me to a whole new network of other computer science majors from across the country; I came to depend on that network as I continued on in my career at both Google and even Microsoft.
We are thrilled to collaborate with a group of individuals and companies, including Expero, GRAKN.AI, Hortonworks and IBM, in launching a new project — JanusGraph — under The Linux Foundation to advance the state-of-the-art in distributed graph computation.
JanusGraph is a fork of the popular open source project Titan, originally released in 2012 by Aurelius, and subsequently acquired by DataStax. Titan has been widely adopted for large-scale distributed graph computation and many users have contributed to its ongoing development, which has slowed down as of late: there have been no Titan releases since the 1.0 release in September 2015, and the repository has seen no updates since June 2016.
This new project will reinvigorate development of the distributed graph system to add new functionality, improve performance and scalability, and maintain a variety of storage backends.
The name "Janus" comes from the name of a Roman god who looks simultaneously into the past to the Titans (divine beings from Greek mythology) as well as into the future.
All are welcome to participate in the JanusGraph project, whether by contributing features or bug fixes, filing feature requests and bugs, improving the documentation or helping shape the product roadmap through feature requests and use cases.
Get involved by taking a look at our website and browse the code on GitHub.
Posted by Parisa Tabriz, Security Princess & Enigma Program Co-Chair
Last year we helped launch USENIX Enigma, a conference focused on bringing together security and privacy experts from academia, industry, and public service. After a successful first run, we’re supporting Enigma again this year and looking forward to more great talks and an ever-engaging hallway track!
Our speakers this year include practitioners from many tech industry leaders, researchers and professors at universities from around the world, and civil servants working at agencies in the U.S. and abroad. In addition to sessions focused specifically on software security, spam and abuse, and usability, the program will cover interdisciplinary topics, like the intersection of security and artificial intelligence, neuroscience, and society.
I’m also very proud to have some of my Google colleagues speaking at Enigma:
Sunny Consolvo will present results from a qualitative study of the privacy and security practices and challenges of survivors of intimate partner abuse. Sunny will also share how technology creators can better support the victims and survivors of such abuse.
Damian Menscher has been battling botnets for a decade at Google and has witnessed the evolution of Distributed Denial-of-Service (DDoS) scaling and attack ingenuity. Damian will describe his operation of a DDoS honeypot, and share specific things he learned while protecting KrebsOnSecurity.com.
Emily Schechter will be talking about driving HTTPS adoption on the web. She’ll go over some of the unexpected speed bumps major web sites have encountered, share how Chrome approaches feature changes that encourage HTTPS usage, and discuss what’s next to get to a default encrypted web.
As we did last year, my program co-chair, David Brumley, and I are developing a program full of short, thought-provoking presentations followed by lively discussion. Our program committee has worked closely with each speaker to help them craft the best version of their talk. Everyone is excited to share them, and there’s still time to register! I hope to see many of you in Oakland at USENIX Enigma later this month.
PS: Warning! Self-serving Google notice ahead… We’re hiring! We believe that most security researchers do what they do because they love what they do. What we offer is a place to do what you love—but in the open, on real-world problems, and without distraction. Please reach out to us if you’re interested.
CSSI Three-Day Takeover! Day Two: Catching Up With CSSI’ers
Today, we’re catching up with a few of our CSSI students from this past summer. We’ve asked the students to share highlights from their time at CSSI and how the program impacted them for their future academic and professional careers.
Haven is a first year student at University of Arkansas where she’s majoring in Computer Science and Mathematics.
Why did you apply to CSSI?
To be honest, I’d never taken a class in computer science and I didn’t have internet at home, so my only experience is in what I picked up troubleshooting tech problems for teachers and watching videos on Khan Academy. My goal for the summer was to gain some hands on experience with software.
What shocked you the most about the program?
I was surprised that there were so many people like me, I stick out with my family and friends and it was nice to belong. It was nice to develop a community that you can talk to about work, personal life, and share your thoughts because I don’t run into people like that in my day to day. Meeting people that were like me encouraged me to pursue CS.
What’s the most important lesson you learned?
I’m one of six kids, the middle child, single mom, poor family, so I felt like I blended in and didn’t think I was going to go far. I wanted to do amazing things, but I thought it’s not really going to happen. Getting into Google gave me the confidence that I can go far.
Now, Haven is pursuing a double major in Computer Science and Mathematics at the University of Arkansas. Great job, Haven!
Jay is a first year student at the University of Alabama where he’s majoring in Computer Science. Below, he shares his thoughts about his three weeks in Cambridge at the CSSI.
How did you become interested in Computer Science and CSSI?
In middle school, I developed a love for technology and was the go-to person at my school who assisted teachers with IT. This combined with my passion for giving back to my community led me to Computer Science. I wanted to pursue a subject where I’m able to build technology that will impact underserved populations and help others.
What was the most important lesson you learned at CSSI?
That it’s best to work in teams. During the project week, I was paired with two other CSSI classmates and together we built a web app. We leaned on each others’ talents to make it possible. Now at school, I meet weekly with my CS classmates preparing for technical interviews and we help each other with internship applications. It’s really helpful because not as many people are as social as I am, but it’s something we can all relate to and can feed off of each others' energy. They’re shooting technical questions at me and telling me what to improve on and I can tell them how to talk to people.
What were you most shocked by?
The amount of talent that I was surrounded by … the instruction and the accelerated students who all had ideas about how they wanted to change the world. I was the only student at my High School who was interested in Computer Science, so being able to come to a place where there are 29 other students who are just like you, interested in the same stuff and they’re thinking about how they can use it to change the world was really meaningful to me.
Thank you for sharing your CSSI memories with us, Haven and Jay!
Clickhereto apply today!
Introducing insights in the Google My Business API
Posted by Aditya Tendulkar, Product Manager, Google My Business
Today we are introducing business location insights in the Google My Business API to make it easier for third-party application developers and large multi-location brands to programmatically access location insights such as total number of searches, views and actions that let business owners track and analyze where and how people are finding them on Google.
Developers can now use the Google My Business API to request up to 18 months worth of data for each of their business locations and build applications that aggregate and visualize these insights in actionable ways. For example, a coffee shop with hundreds of locations can now easily compare and understand trends across their different locations such as number of user views, click requests for directions, phone calls, and more. They can use these insights to better allocate resources across locations and track how marketing activities affect their business.
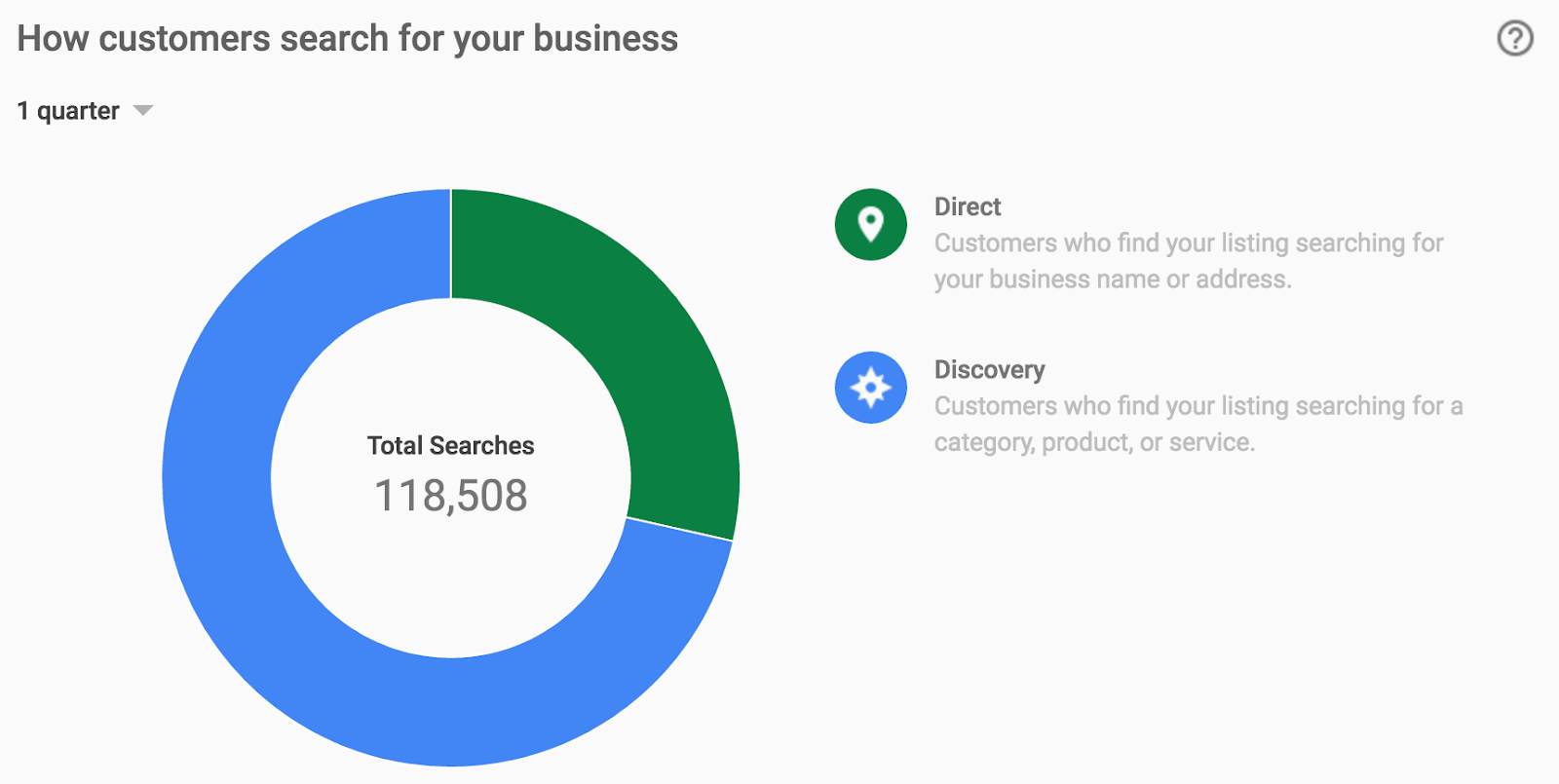
This new API functionality brings the features from our Google My Business dashboard into your own data analysis tools. Web interface users might generate a chart of the last 90 days of Google My Business information:
Example data visible via the Google My Business web dashboard
Now the underlying data is available via the API. It's easy to get started with our new developer documentation. Here's a simple HTML request that provides a breakdown of how many searches a business listing is getting on Google Search and Google Maps:
Example data visible via the Google My Business web dashboard
With this new feature, Google My Business API users can optimize their listings to drive customer actions through understanding key insights about how customers are searching for their business on Google, and what actions they are taking once they find it. These insights are also available on Google My Business web and mobile, allowing users to keep track of key trends from anywhere.
To learn more about the Google My Business API and to apply for access, visit our developer page. Questions or feedback? Contact the API team on the Google My Business API Forum.
CSSI Three-Day Takeover! Day One: Computer Science Summer Institute and Generation Google Scholarship Applications Are Open
We are now accepting applications for the 2017Computer Science Summer Institute, as well as the 2017Generation Google Scholarship. Learn more about both programs below andapply today!
What
TheComputer Science Summer Institute (CSSI)is a three-week introduction to computer science for graduating high school seniors with a passion for technology.Students will learn programming fundamentals directly from Google engineers, get an inside look at some of Google's most exciting, emerging technologies, and even design and develop their very own application with fellow participants.
TheGeneration Google Scholarshiphelps aspiring computer scientists from underrepresented groups excel in technology and become leaders in the field. Selected students will receive10,000 USD (for those studying in the US) or 5,000 CAD (for those studying in Canada) for the 2017-2018 school year. As part of the scholarship, current high school seniors who are entering their first year of university in Fall 2017 will be required to attend CSSI in the summer of 2017.
Where & When
We offer two types of sessions at CSSI: commuter and residential.In the residential camps, housing and transportation will be provided. In the day camps, students will be provided with a travel stipend and expected to commute into the respective Google offices for each day of CSSI. Students within a specified mileage distance from the respective day-camp offices will automatically be considered for those sites. The sites will be taking place in Mountain View, CA, Los Angeles, CA, Chicago, IL, New York, NY, Pittsburgh, PA, Atlanta, GA, Cambridge, MA, and Seattle, WA.
Who
We are looking for students eager to spend a few weeksimmersed in the Google life -- tackling interestingtechnical problems, working collaboratively and having fun. The program is committed to addressing diversity in the field of computer science and is open to all qualified high school seniors who intend to major in computer science at a four year university in the US or Canada.
Why
Google is committed to increasing the enrollment and retention of students in the field of computer science. These programs offer an intensive, interactive and fun experience that seeks to inspire the tech leaders and innovators of tomorrow. We want students to leave empowered, heading into their first year of college armed with technical skills and a unique learning experience that can only be found at Google. We aim to expose selected students to key programming concepts while enabling them to tackle the challenging problems in CS by creating a safe, comfortable environment to learn, play, break, and build.
Apply
Visit ourGoogle for Education websitefor more information and to apply.The application deadline is March 2, 2017. Final decisions will be announced in early May.
Making important business decisions is often a slow process, regardless of industry or company size. In a world where innovation is increasingly important, speed is a necessity. But how does an organization streamline its decision-making process? For many companies, the answer is data. In fact, highly data-driven organizations are three times more likely than others to report significant improvement in decision-making, according to PwC research.1
When looking for meaningful insights to drive innovation and growth, market research is often a go-to data source. The problem many companies face is that market research can feel like a roadblock because it can take months to get the data.
At Lenovo, the leading PC manufacturer worldwide, constantly evolving and improving products is required to remain competitive. “We have to make decisions today for products two years from now,” says Sarah Kennedy, User Experience Researcher at Lenovo. To keep the decision-making process moving, Sarah’s team uses Google Surveys 360 for fast and accurate data. Bringing consumer insights to the table in the early stages of product development helps her team get buy-in from senior stakeholders at a faster pace. “Within seven days, we can get results that would normally take us a month,” says Sarah.
"We put an emphasis on innovation. Collecting competitive data and industry benchmarks is critical to do this. Surveys 360 helps us get data on the current state of the market. The results are reliable and delivered at the speed we need so our teams can continue developing the best products without delay."
– Corinna Proctor, Director of User & Design Research, Lenovo
See the Lenovo story here.
Google Surveys 360 provides businesses with the data they need quickly, accurately, and affordably. Choose your target audience, write your survey, and get answers in as little as three days. Get started today.
Happy surveying! 1PwC's Global Data and Analytics Survey, Big Decisions™, Base: 1,135 senior executives, Global, May 2016
Posted by Kevin Fields, Product Marketing Manager, Google Surveys team
Please join me in extending a hearty digital “Huzzah!” to the Apache Beam community: as announced today, Apache Beam is an official graduate of the Apache Incubator and is now a full-fledged, top-level Apache project. This achievement is a direct reflection of the hard work the community has invested in transforming Beam into an open, professional and community-driven project.
11 months ago, Google and a number of partners donated a giant pile of code to the Apache Software Foundation, thus forming the incubating Beam project. The bulk of this code composed the Google Cloud Dataflow SDK: the libraries that developers used to write streaming and batch pipelines that ran on any supported execution engine. At the time, the main supported engine was Google’s Cloud Dataflow service with support for Apache Spark and Apache Flink in development); as of today there are five officially supported runners. Though there were many motivations behind the creation of Apache Beam, the one at the heart of everything was a desire to build an open and thriving community and ecosystem around this powerful model for data processing that so many of us at Google spent years refining. But taking a project with over a decade of engineering momentum behind it from within a single company and opening it to the world is no small feat. That’s why I feel today’s announcement is so meaningful.
With that context in mind, let’s look at some statistics squirreled away in the graduation maturity model assessment:
Out of the ~22 large modules in the codebase, at least 10 modules have been developed from scratch by the community, with little to no contribution from Google.
Since September, no single organization has had more than ~50% of the unique contributors per month.
The majority of new committers added during incubation came from outside Google.
And for good measure, here’s a quote from the Vice President of the Apache Incubator, lifted from the public Apache incubator general discussions list where Beam’s graduation was first proposed:
“In my day job as well as part of my work at Apache, I have been very impressed at the way that Google really understands how to work with open source communities like Apache. The Apache Beam project is a great example of this and is a great example of how to build a community." -- Ted Dunning, Vice President of Apache Incubator
The point I’m trying to make here is this: while Google’s commitment to Apache Beam remains as strong as it always has been, everyone involved (both within Google and without) has done an excellent job of building an open source project that’s truly open in the best sense of the word.
This is what makes open source software amazing: people coming together to build great, practical systems for everyone to use because the work is exciting, useful and relevant. This is the core reason I was so excited about us creating Apache Beam in the first place, the reason I’m proud to have played some small part in that journey, and the reason I’m so grateful for all the work the community has invested in making the project a reality.
Naturally, graduation is only one milestone in the lifetime of the project, and we have many more ahead of us, but becoming top-level project is an indication that Apache Beam now has a development community that is ready for prime time.
That means we’re ready to continue pushing forward the state of the art in stream and batch processing. We’re ready to bring the promise of portability to programmatic data processing, much in the way SQL has done so for declarative data analysis. We’re ready to build the things that never would have gotten built had this project stayed confined within the walls of Google. And last but perhaps not least, we’re ready to recoup the vast quantities of text space previously consumed by the mandatory “(incubating)” moniker accompanying all of our initial mentions of Apache Beam!
But seriously, whatever your motivation, please consider joining us along the way. We have an exciting road ahead.
By Tyler Akidau, Apache Beam PMC and Staff Software Engineer at Google
Posted by Andrew Gerrand, Eric Grosse, Rob Pike, Eduardo Pinheiro and Dave Presotto, Google Software Engineers
Existing mechanisms for file sharing are so fragmented that people waste time on multi-step copying and repackaging. With the new project Upspin, we aim to improve the situation by providing a global name space to name all your files. Given an Upspin name, a file can be shared securely, copied efficiently without “download” and “upload”, and accessed by anyone with permission from anywhere with a network connection.
Our target audience is personal users, families, or groups of friends. Although Upspin might have application in enterprise environments, we think that focusing on the consumer case enables easy-to-understand and easy-to-use sharing.
File names begin with the user’s email address followed by a slash-separated Unix-like path name:
Any user with appropriate permission can access the contents of this file by using Upspin services to evaluate the full path name, typically via a FUSE filesystem so that unmodified applications just work. Upspin names usually identify regular static files and directories, but may point to dynamic content generated by devices such as sensors or services.
If the user wishes to share a directory (the unit at which sharing privileges are granted), she adds a file called Access to that directory. In that file she describes the rights she wishes to grant and the users she wishes to grant them to. For instance,
allows Joe and Mae to read any of the files in the directory holding the Access file, and also in its subdirectories. As well as limiting who can fetch bytes from the server, this access is enforced end-to-end cryptographically, so cleartext only resides on Upspin clients, and use of cloud storage does not extend the trust boundary.
Upspin looks a bit like a global file system, but its real contribution is a set of interfaces, protocols, and components from which an information management system can be built, with properties such as security and access control suited to a modern, networked world. Upspin is not an “app” or a web service, but rather a suite of software components, intended to run in the network and on devices connected to it, that together provide a secure, modern information storage and sharing network. Upspin is a layer of infrastructure that other software and services can build on to facilitate secure access and sharing. This is an open source contribution, not a Google product. We have not yet integrated with the Key Transparency server, though we expect to eventually, and for now use a similar technique of securely publishing all key updates. File storage is inherently an archival medium without forward secrecy; loss of the user’s encryption keys implies loss of content, though we do provide for key rotation.
It’s early days, but we’re encouraged by the progress and look forward to feedback and contributions. To learn more, see the GitHub repository at upspin.
Posted by Takeshi Hagikura, Developer Programs Engineer
At Google I/O last year we announced ConstraintLayout,
which enables you to build complex layouts while maintaining a flat view
hierarchy. It is also fully supported in Android Studio’s Vis…
Feb 21, 2017
Building trust and increasing transparency with MRC-accredited measurement
Measurement has been top of mind in our recent conversations with advertisers, and for good reason. As we’ve said many times, “If you can’t measure it, how do you know it worked?” Committing to measurement is critical, but just the first step. We believe that that the industry needs metrics that are trusted, transparent and easily verified. Today, we’re pleased to share several updates on the work we’re doing with third party verification and audit partners to ensure that the metrics available from Google are objective and accurate.
Transparency and trust are the core principles of our measurement strategy. We strongly believe in the need for third-party accreditation through the Media Rating Council (MRC). We gained our first accreditations back in 2006, and for over ten years we’ve partnered with the MRC, advocating for standards across the industry and contributing to ongoing discussions that set guidelines for measuring the effectiveness of ads. We currently maintain over 30 MRC accreditations across display and video, desktop and mobile web, mobile apps, and clicks, plays, impressions and viewability.
MRC accreditation for 3rd party viewability reporting on YouTube
Since 2015, we’ve completed integrations with Moat, Integral Ad Science and DoubleVerify to enable third-party viewability reporting on YouTube. These integrations offer advertisers additional choice for measuring viewability on YouTube, alongside Active View.
Today, we’re announcing that each of these integrations will undergo a stringent, independent audit for MRC accreditation. The audit will validate that data collection, aggregation and reporting for served video impressions, viewable impressions, related viewability statistics and General Invalid Traffic (GIVT) across desktop and mobile for each integration adheres to MRC and IAB standards. In short, advertisers will have even greater confidence in the metrics returned by these third party partners about their campaigns on YouTube.
“Google’s announcement that they are undertaking an independent audit of their 3rd party viewability reporting integrations is a positive step forward for marketers. At the ANA, our goal is to create transparency for the advertising supply chain. This action from Google today demonstrates their commitment to partnering with us to deliver this goal.”
—Bob Liodice, President and CEO, Association for National Advertisers
New MRC accreditations for DoubleClick and AdWords
Our commitment to MRC accreditation goes beyond our media to include our platform solutions as well. We maintain several accreditations for DoubleClick already, and today we’re announcing that we are now fully accredited for video impressions and viewability statistics for desktop web, mobile web and mobile app in DoubleClick Campaign Manager.
We are also seeking MRC accreditation for video impressions and viewability statistics and GIVT detection for display and video in both AdWords and DoubleClick Bid Manager. These MRC audits will span across all video available through these buying platforms — including YouTube and partner inventory.
“Google’s commitment to MRC’s initiatives has been unwavering over time, and their participation in industry standards projects has been helpful. We look forward to working on these new audits and expanding the industry’s trust as it relates to YouTube’s third party integrations and DoubleClick Bid Manager.”
—George Ivie, CEO and Executive Director, Media Rating Council
“Google’s announcement to bring more media transparency is important progress that will help move the industry forward. At P&G, we are encouraged by Google’s actions, which should make a positive impact on creating a clean and productive media supply chain.”
—Marc Pritchard, Chief Brand Officer, Procter & Gamble
With so much activity underway, we know that it can be difficult to stay current. For an up to date list of all MRC accreditations, click here.
Transparency and trust are fundamental to measurement, and they’re fundamental to our strategy for giving marketers and publishers the metrics and insights they need to make better decisions. A solid foundation has been created, but there is much more work to do. In 2017, we’ll continue to seek ways to raise the bar on transparent and trustworthy measurement, and we welcome your partnership along the way.
Posted by Babak Pahlavan
Senior Director of Product Management, Analytics Solutions and Measurement, Google
Feb 20, 2017
Do you like the new look of the Maps APIs tutorials?
Until recently, our docs have focused on describing features rather than telling a story. We chatted to some developers and came up with a new design for our tutorials. We’d love to know what you think of them.
Developers tell us they want quick, straightforward guides on how to integrate the Google Maps APIs into their app. The most common thing people want to do is to add a map with a marker. Just show me how to do that.
Developers are also looking for complete, step-by-step tutorials for the most common use cases. Guides that go all the way from a to z, with no deviations.
And they want code. Front and foremost. All the code.
Here are some examples of the new-look tutorials:
Adding a map with a marker – web, Android and iOS.
Styling your map – web, Android and iOS.
Showing the business or other point of interest at the current location – Android and iOS.
All the redesigned tutorials for the Google Maps JavaScript API.
Each tutorial provides the entire development project, especially useful for the native mobile APIs. The doc page goes hand in hand with a new sample app on GitHub. For example, here’s the code for the current place tutorial on Android.
Each page includes a visual illustration of what you’ll achieve by following the tutorial. A working demo is ideal (such as the visualizing data tutorial for the Google Maps JavaScript API), otherwise a screenshot (as we’ve done for the native mobile APIs).
We want to make it easy for developers to find the guides. So, we’re adding tutorial showcases to the API overview pages. To date we’ve created the showcases for Android, iOS, and JavaScript. We’re also collecting together all the tutorials for the Maps JavaScript API in one place.
We’ve made a good start, but there’s plenty of change still to come. What would you like to see more of? Are we on the right track? The tech writing team would love your ideas—please add comments to this post.
Posted by Sarah Maddox, Technical Writer, Google Maps APIs
Feb 16, 2017
Understanding differences between corporate and consumer Gmail threats
Posted by Ali Zand and Vijay Eranti, Anti-Abuse Research and Gmail Abuse
We are constantly working to protect our users, and quickly adapt to new online threats. This work never stops: every minute, we prevent over 10 million unsafe or unwanted emails from reaching Gmail users and threatening them with malicious attachments that infect a user’s machine if opened, phishing messages asking for banking or account details, and omnipresent spam. A cornerstone of our defense is understanding the pulse of the email threat landscape. This awareness helps us to anticipate and react faster to emerging attacks.
Today at RSA, we are sharing key insights about the diversity of threats to corporate Gmail inboxes. We’ve highlighted some of our key findings below; you can see our full presentation here. We’ve already incorporated these insights to help keep our G Suite users safe, and we hope that by exposing these nuances, security and abuse professionals everywhere can better understand their risk profile and customize their defenses accordingly.
How threats to corporate and consumer inboxes differ While spam may be the most common attack across all inboxes, did you know that malware and phishing are far more likely to target corporate users? Here’s a breakdown of how attacks stack up for corporate vs. personal inboxes:
Different threats to different types of organizations
Attackers appear to choose targets based on multiple dimensions, such as the size and the type of the organization, its country of operation, and the organization’s sector of activity. Let’s look at an example of corporate users across businesses, nonprofits, government-related industries, and education services. If we consider business inboxes as a baseline, we find attackers are far more likely to target nonprofits with malware, while attackers are more likely to target businesses with phishing and spam.
These nuances go all the way down to the granularity of country and industry type. This shows how security and abuse professionals must tailor defenses based on their personalized threat model, where no single corporate user faces the same attacks.
Constant improvements to corporate Gmail protections
Research like this enables us to better protect our users. We are constantly innovating to better protect our users, and we’ve already implemented these findings into our G Suite protections. Additionally, we have implemented and rolled out several features that help our users stay safe against these ever-evolving threats.
The forefront of our defenses is a state-of-the-art email classifier that detects abusive messages with 99.9% accuracy.
To protect yourself from unsafe websites, make sure to heed interstitial warnings that alert you of potential phishing and malware attacks.
Use many layers of defense: we recommend using a security key enforcement (2-step verification) to thwart attackers from accessing your account in the event of a stolen password.
To ensure your email contents’ stays safe and secure in transit, use our hosted S/MIME feature.
Use our TLS encryption indicator, to ensure only the intended recipient can read your email.
We will never stop working to keep our users and their inboxes secure. To learn more about how we protect Gmail, check out this YouTube video that summarizes the lessons we learned while protecting Gmail users through the years.
Feb 16, 2017
And the winners of the Google Play Indie Games Contest in Europe are…
Posted byMatteo Vallone, Google Play Games Business Development
Today, at Saatchi Gallery in London, we hosted the final event of the firstGoogle Play Indie Games Contestin Europe. The 20 finalists,selected from nearly 1000 submissions, came from 12 countries to showcase their games to an excited room of gamers, industry experts and press. Selected based on the votes of the attendees and the Google Play team, the Top 10 pitched in front of ajury of industry expertswho chose the top winners.
Stay tuned for more pictures and a video of the event.
Without further ado, join us in congratulating the winners!
Winner & Unity prize winner:
Reigns, by Nerial, from the United Kingdom
You are the King. For each decision, you only have two choices. Survive the exercise of power and the craziness of your advisors… as long as you can.
Runners up:
The Battle of Polytopia, by Midjiwan AB, from Sweden
A turn based strategic adventure. It’s a game about ruling the world, fighting evil AI tribes, discovering new lands and mastering new technologies.
Causality, by Loju, from the United Kingdom
A puzzle about manipulating time, altering the sequence of events and changing the outcome of each level to help a group of astronauts find a route to safety.
The other top games selected by the event attendees and the Google Play team are:
Blind Drive, by Lo-Fi People, from Israel
You’re driving blindfolded as a mysterious voice gives you suicidal commands on the phone. Survive on-rushing vehicles using only your hearing to guide you.
Gladiabots, by GFX47, from France
A competitive tactical game in which you design the AI of your robot squad. Use your own strategy, refine it online and fight for the top of the leaderboard.
Happy Hop: Kawaii Jump, by Platonic Games, from Spain
This isn’t just an original one-tap endless hopper, it’s also the cutest one. Ever wondered what’s in the end of the rainbow? That would be Happy Hop.
Lost in Harmony, by Digixart Entertainment, from France
Experience music in a new way with the combination of rhythmic tapping and choreographic runner to go through two memorable journeys with Kaito and M.I.R.A.I.
Paper Wings, by Fil Games, from Turkey
A fast-paced arcade game which puts you in control of an origami bird. Avoid the hazards and collect the falling coins to keep your paper bird alive.
Pinout, by Mediocre, from Sweden
A breathtaking pinball arcade experience: race against time in a continuous journey through this canyon of pulsating lights and throbbing retro wave beats.
Rusty Lake: Roots, by Rusty Lake, from Netherlands
James Vanderboom’s life drastically changes when he plants a special seed in the garden. Expand your bloodline by unlocking portraits in the tree of life.
Check out the prizes
The prizes of this contest were designed to help the winners showcase their art and grow their business on Android and Google Play, including:
YouTube influencer campaigns worth up to 100,000 EUR
Premium placements on Google Play
Tickets to Google I/O 2017 and other top industry events
Promotions on our channels
Special prizes for the best Unity game
Andmore!
What’s next?
The week is not over just yet for Indie games developers. Tomorrow we are hosting theIndie Games Workshopfor all indie games developers from across EMEA in the new Google office in Kings Cross.
It’s been really inspiring to see the enthusiasm around this inaugural edition, and the quality and creativity of the indie games developed across the eligible European countries. We are looking forward to bringing a new edition of the contest to you in late 2017.
How useful did you find this blogpost?
★★★★★
What is Google Data?
Google Data is the only site where you can get news from 60+ official Google blogs all in one place. We have published 24,364 official posts since January 2005.