(Cross-posted from The Keyword)
One of the core promises of Google Docs is to help you and your team go from collecting ideas to achieving your goals as quickly and easily as possible. That’s why last month we launched Explore in Docs, Sheets and Slides — with machine intelligence built right in — to help your team create amazing presentations, spreadsheets and documents in a fraction of the time it used to take.
Today, we’re introducing five new time-saving features designed to speed up and simplify the way you work, so you can focus on bringing your team’s ideas to life.
1. Spend less time figuring out who owns what with Action Items
According to research by the McKinsey Global Institute, employees spend about 20 percent of their work week — nearly an entire day — searching for details internally and tracking down colleagues for answers. This can be especially true when a document is full of ideas, requests and comments, making it difficult to get a clear sense of who’s responsible for what.
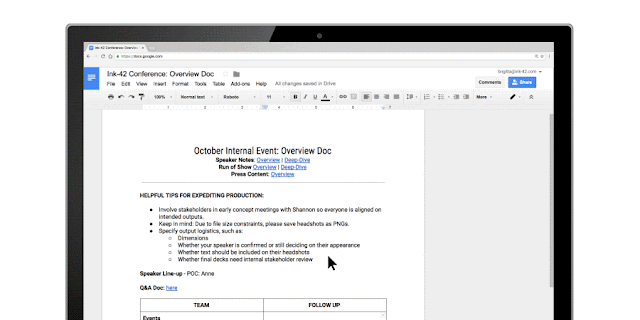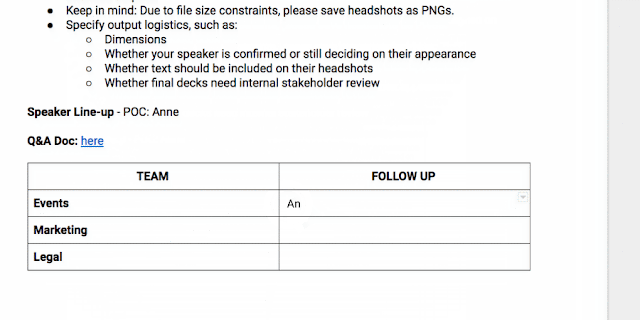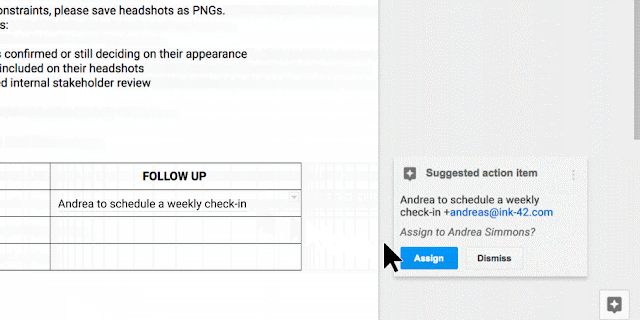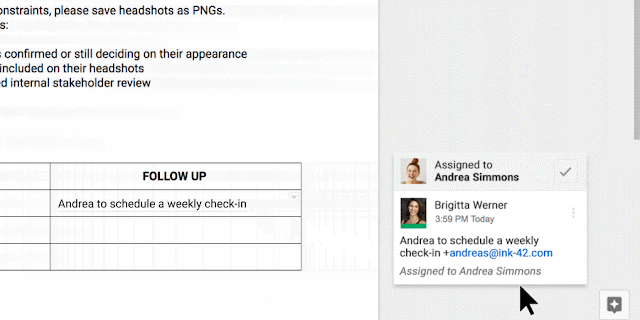
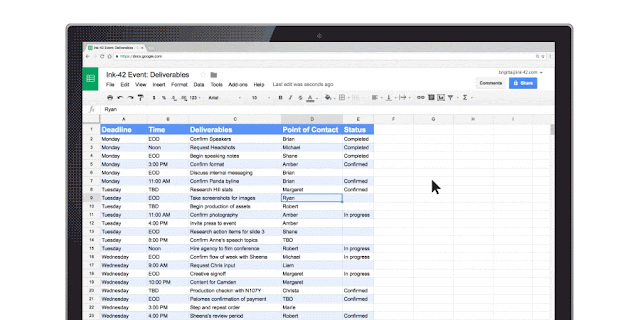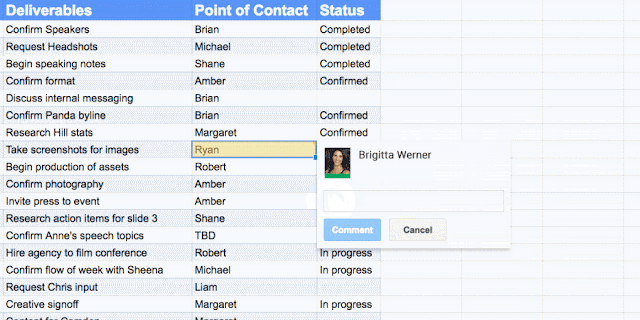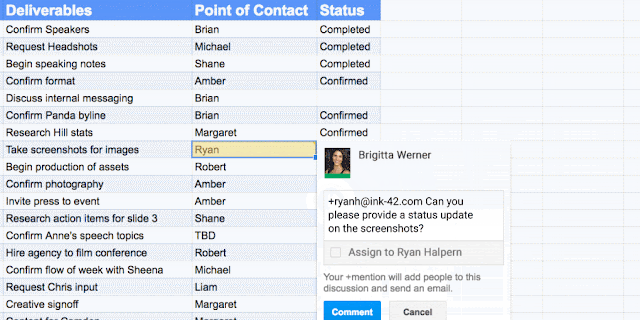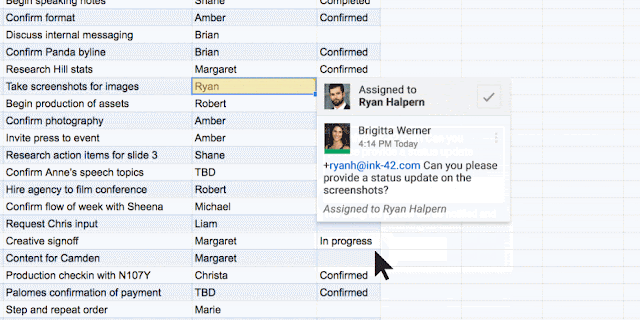
To help keep your projects moving, when you type phrases like “Ryan to follow up on the keynote script,” or “Andrea to schedule a weekly check in” on desktop, Docs will intelligently suggest an Action Item to assign to the right person, thanks to Natural Language Processing (NLP).
You can also manually assign an Action Item to someone in the Docs, Sheets and Slides desktop and mobile apps by mentioning their name in a comment and checking the new Action Item box. The assignee will get an email notification and see the Action Item(s) clearly highlighted with a blue bar when they open the file.
2. Spend less time searching for the files that need attention
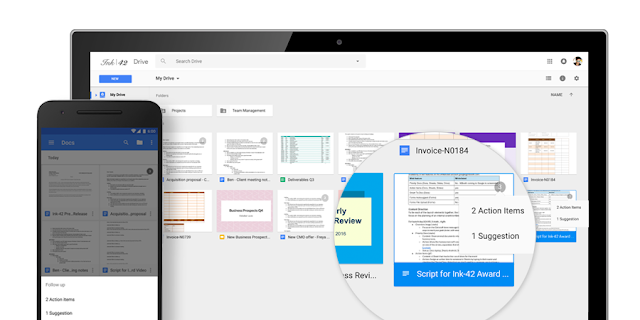
Once Action Items have been assigned, it’s easy for team members to identify documents, spreadsheets and presentations that need their attention. The next time they visit Docs, Sheets, Slides (or Drive) from their laptops or mobile apps, they’ll see a badge on any files with Action Items assigned to them, plus any unresolved suggestions that others have made to their files.
3. Spend less time building questions with smarter Forms
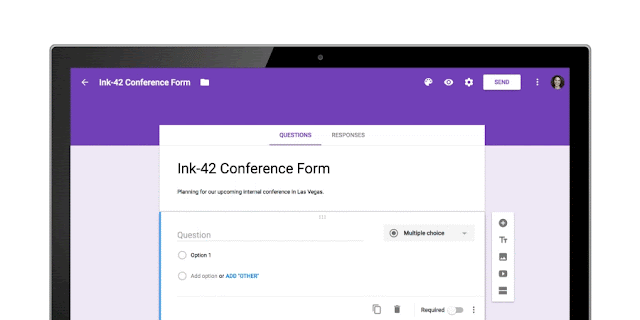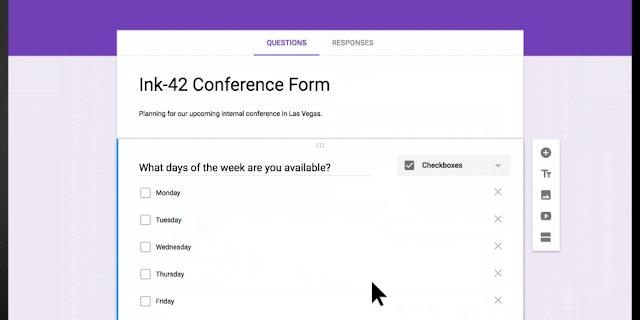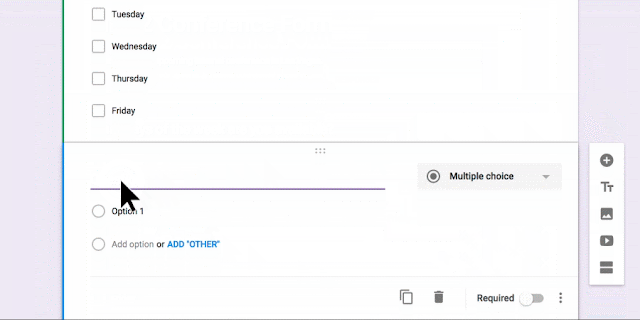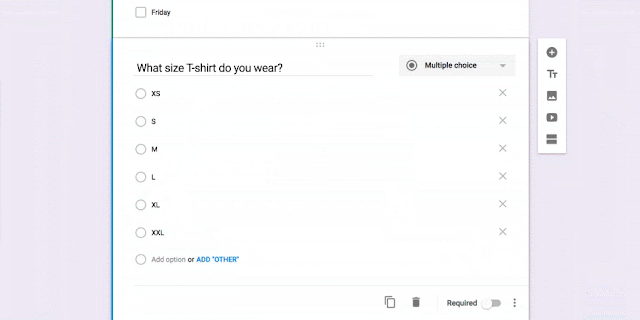
Since its launch in 2008, more than a billion questions have been asked in Forms, allowing us to identify common patterns, like question types and the response options that usually go with them. With the help of neural networks, we can now predict the type of question you’re asking and suggest potential responses for you to choose from, giving you back about 25 percent of the time you used to spend creating a Form.
Let’s say you’re planning an all-day event at the office and need to know which day works best for your team. When you type “What days are you available next week?” Forms will intelligently determine that “Checkbox” is the ideal question type, and generate related response options that you can add one by one or all together.
Also debuting today is a top-requested feature from our business and education customers — the new “File upload” question type. Your respondents can now upload files from their computer or Drive — all of which are neatly collected for you in a new Drive folder. Note: This feature is only available for G Suite customers in Forms shared within their organization.
4. Spend less time typing with a set of new voice commands
Last year, we launched Voice typing in Docs on the web to help you capture ideas, big and small, without lifting a finger. Today, we’re adding more ways to format and customize content with commands for changing text color, deleting words, inserting links and comments, plus a number of other ways to format, hands-free.
5. Spend less time switching between apps to get things done
We want you to be as productive and collaborative as possible, regardless of the tools you choose to work with, so we’ve partnered with Slack to make it even easier to work with Google Docs files. With a click of the “+” button in Slack, you can bring files from Drive directly into a conversation with your team, or create new Docs, Sheets and Slides files right from Slack. You can check out more details on Slack’s blog.
With the introduction of Explore, and more and more updates to products that build in machine intelligence, taking back time spent on mundane, repetitive tasks will only get easier with G Suite. Now, you can focus your energy on creative and strategic work, not busy work.
Launch Details
Release track:
- Launching to both Rapid release and Scheduled release
-
- Assigned action items
- Priority badges
- Voice typing improvements
- Slack integration
- Launching to Rapid release, with Scheduled release coming on November 2nd, 2016
-
- Suggested action items
- Suggested response options in Forms
- Launching to Rapid release, with Scheduled release coming on November 9th, 2016
-
Editions:
Available to all G Suite editions
Rollout pace:
Gradual rollout (potentially longer than 3 days for feature visibility)
Impact:
All end users
Action:
Change management suggested/FYI
More Information
Help Center: Add, edit, reply, or delete comments
Help Center: Edit your form
Help Center: Type with your voice
Slack Blog
Launch release calendar
Launch detail categories
Get these product update alerts by email
Subscribe to the RSS feed of these updates