reCAPTCHA just got easier (but only if you’re human)
October 25th, 2013 | Published in Google Online Security
For over a decade, CAPTCHAs have used visual puzzles to help webmasters keep automated software from engaging in abusive activities on their sites. However, over the last few years advances in artificial intelligence have reduced the gap between human and machine capabilities in deciphering distorted text. Today, a successful CAPTCHA solution needs to go beyond just relying on text distortions to separate man from machine.
The reCAPTCHA team has been performing extensive research and making steady improvements to learn how to better protect users from attackers. As a result, reCAPTCHA is now more adaptive and better-equipped to distinguish legitimate users from automated software.
The updated system uses advanced risk analysis techniques, actively considering the user’s entire engagement with the CAPTCHA—before, during and after they interact with it. That means that today the distorted letters serve less as a test of humanity and more as a medium of engagement to elicit a broad range of cues that characterize humans and bots.
As part of this, we’ve recently released an update that creates different classes of CAPTCHAs for different kinds of users. This multi-faceted approach allows us to determine whether a potential user is actually a human or not, and serve our legitimate users CAPTCHAs that most of them will find easy to solve. Bots, on the other hand, will see CAPTCHAs that are considerably more difficult and designed to stop them from getting through.
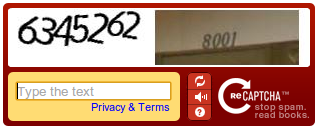
A new and easier numeric CAPTCHA
Humans find numeric CAPTCHAs significantly easier to solve than those containing arbitrary text and achieve nearly perfect pass rates on them. So with our new system, you’ll encounter CAPTCHAs that are a breeze to solve. Bots, however, won’t even see them. While we’ve already made significant advancements to reCAPTCHA technology, we’ll have even more to report on in the next few months, so stay tuned.