Syntactic Ngrams over Time
May 23rd, 2013 | Published in Uncategorized
We are proud to announce the release of a very large dataset of counted dependency tree fragments from the English Books Corpus. This resource will help researchers, among other things, to model the meaning of English words over time and create better natural-language analysis tools. The resource is based on information derived from a syntactic analysis of the text of millions of English books.
Sentences in languages such as English have structure. This structure is called syntax, and knowing the syntax of a sentence is a step towards understanding its meaning. The process of taking a sentence and transforming it into a syntactic structure is called parsing. At Google, we parse a lot of text every day, in order to better understand it and be able to provide better results and services in many of our products.
There are many kinds of syntactic representations (you may be familiar with sentence diagramming), and at Google we've been focused on a certain type of syntactic representation called "dependency trees". Dependency-trees representation is centered around words and the relations between them. Each word in a sentence can either modify or be modified by other words. The various modifications can be represented as a tree, in which each node is a word.
For example, the sentence "we really like syntax" is analyzed as:
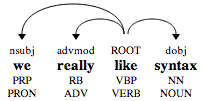
The verb "like" is the main word of the sentence. It is modified by a subject (denoted nsubj) "we", a direct object (denoted dobj) "syntax", and an adverbial modifier "really".
An interesting property of syntax is that, in many cases, one could recover the structure of a sentence without knowing the meaning of most of the words. For example, consider the sentence "the krumpets gnorked the koof with a shlap". We bet you could infer its structure, and tell that group of something which is called a krumpet did something called "gnorking" to something called a "koof", and that they did so with a "shlap".
This property by which you could infer the structure of the sentence based on various hints, without knowing the actual meaning of the words, is very useful. For one, it suggests that a even computer could do a reasonable job at such an analysis, and indeed it can! While still not perfect, parsing algorithms these days can analyze sentences with impressive speed and accuracy. For instance, our parser correctly analyzes the made-up sentence above.

Let's try a more difficult example. Something rather long and literary, like the opening sentence of One hundred years of solitude by Gabriel García Márquez, as translated by Gregory Rabassa:
Many years later, as he faced the firing squad, Colonel Aureliano Buendía was to remember that distant afternoon when his father took him to discover ice.

Pretty good for an automatic process, eh?
And it doesn’t end here. Once we know the structure of many sentences, we can use these structures to infer the meaning of words, or at least find words which have a similar meaning to each other.
For example, consider the fragments:
"order a XYZ"
"XYZ is tasty"
"XYZ with ketchup"
"juicy XYZ"
By looking at the words modifying XYZ and their relations to it, you could probably infer that XYZ is a kind of food. And even if you are a robot and don't really know what a "food" is, you could probably tell that the XYZ must be similar to other unknown concepts such as "steak" or "tofu".
But maybe you don't want to infer anything. Maybe you already know what you are looking for, say "tasty food". In order to find such tasty food, one could collect the list of words which are objects of the verb "ate", and are commonly modified by the adjective "tasty" and "juicy". This should provide you a large list of yummy foods.
Imagine what you could achieve if you had hundreds of millions of such fragments. The possibilities are endless, and we are curious to know what the research community may come up with. So we parsed a lot of text (over 3.5 million English books, or roughly 350 billion words), extracted such tree fragments, counted how many times each fragment appeared, and put the counts online for everyone to download and play with.
350 billion words is a lot of text, and the resulting dataset of fragments is very, very large. The resulting datasets, each representing a particular type of tree fragments, contain billions of unique items, and each dataset’s compressed files takes tens of gigabytes. Some coding and data analysis skills will be required to process it, but we hope that with this data amazing research will be possible, by experts and non-experts alike.
The dataset is based on the English Books corpus, the same dataset behind the ngram-viewer. This time there is no easy-to-use GUI, but we still retain the time information, so for each syntactic fragment, you know not only how many times it appeared overall, but also how many times it appeared in each year -- so you could, for example, look at the subjects of the word “drank” at each decade from 1900 to 2000 and learn how drinking habits changed over time (much more ‘beer’ and ‘coffee’, somewhat less ‘wine’ and ‘glass’ (probably ‘of wine’). There’s also a drop in ‘whisky’, and an increase in ‘alcohol’. Brandy catches on around 1930s, and start dropping around 1980s. There is an increase in ‘juice’, and, thankfully, some decrease in ‘poison’).
The dataset is described in details in this scientific paper, and is available for download here.