Docker + Dataflow = happier workflows
November 30th, 2016 | by Open Source Programs Office | published in Google Open Source
When I first saw the Google Cloud Dataflow monitoring UI — with its visual flow execution graph that updates as your job runs, and convenient links to the log messages — the idea came to me. What if I could take that UI, and use it for something it was never built for? Could it be connected with open source projects aimed at promoting reproducible scientific analysis, like Common Workflow Language (CWL) or Workflow Definition Language (WDL)?
 |
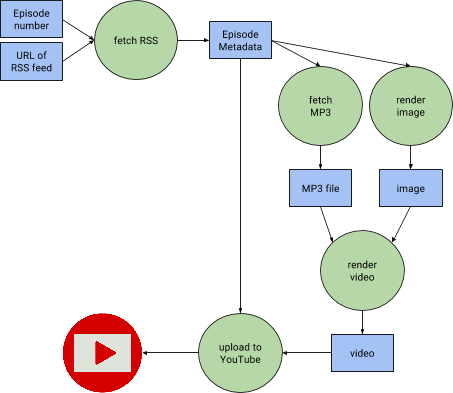
| Screenshot of a Dockerflow workflow for DNA sequence analysis. |
In scientific computing, it’s really common to submit jobs to a local high-performance computing (HPC) cluster. There are tools to do that in the cloud, like Elasticluster and Starcluster. They replicate the local way of doing things, which means they require a bunch of infrastructure setup and management that the university IT department would otherwise do. Even after you’re set up, you still have to ssh into the cluster to do anything. And then there are a million different choices for workflow managers, each unsatisfactory in its own special way.
By day, I’m a product manager. I hadn’t done any serious coding in a few years. But I figured it shouldn’t be that hard to create a proof-of-concept, just to show that the Apache Beam API that Dataflow implements can be used for running scientific workflows. Now, Dataflow was created for a different purpose, namely, to support scalable data-parallel processing, like transforming giant data sets, or computing summary statistics, or indexing web pages. To use Dataflow for scientific workflows would require wrapping up shell steps that launch VMs, run some code, and shuttle data back and forth from an object store. It should be easy, right?
It wasn’t so bad. Over the weekend, I downloaded the Dataflow SDK, ran the wordcount examples, and started modifying. I had a “Hello, world” proof-of-concept in a day.
To really run scientific workflows would require more, of course. Varying VM shapes, a way to pass parameters from one step to the next, graph definition, scattering and gathering, retries. So I shifted into prototyping mode.
I created a new GitHub project called Dockerflow. With Dockerflow, workflows can be defined in YAML files. They can also be written in pretty compact Java code. You can run a batch of workflows at once by providing a CSV file with one row per workflow to define the parameters.
Dataflow and Docker complement each other nicely:
- Dataflow provides a fully managed service with a nice monitoring interface, retries, graph optimization and other niceties.
- Docker provides portability of the tools themselves, and there’s a large library of packaged tools already available as Docker images.
While Dockerflow supports a simple YAML workflow definition, a similar approach could be taken to implement a runner for one of the open standards like CWL or WDL.
To get a sense of working with Dockerflow, here’s “Hello, World” written in YAML:
defn:
name: HelloWorkflow
steps:
- defn:
name: Hello
inputParameters:
name: message
defaultValue: Hello, World!
docker:
imageName: ubuntu
cmd: echo $message
And here’s the same example written in Java:
public class HelloWorkflow implements WorkflowDefn {
@Override
public Workflow createWorkflow(String[] args) throws IOException {
Task hello =
TaskBuilder.named("Hello").input("message", “Hello, World!”).docker(“ubuntu”).script("echo $message").build();
return TaskBuilder.named("HelloWorkflow").steps(hello).args(args).build();
}
}
Dockerflow is just a prototype at this stage, though it can run real workflows and includes many nice features, like dry runs, resuming failed runs from mid-workflow, and, of course, the nice UI. It uses Cloud Dataflow in a way that was never intended — to run scientific batch workflows rather than large-scale data-parallel workloads. I wish I’d written it in Python rather than Java. The Dataflow Python SDK wasn’t quite as mature when I started.
Which is all to say, it’s been a great 20% project, and the future really depends on whether it solves a problem people have, and if others are interested in improving on it. We welcome your contributions and comments! How do you run and monitor scientific workflows today?
By Jonathan Bingham, Google Genomics and Verily Life Sciences

 Developing a better distributed debugging tool is essential to increase the programmability of HPX. Parsa’s project, Scimitar, aims to facilitate the debugging process for HPX programmers by extending the features of GDB, an existing debugger. The project then complements it with new commands for easier switching between localities across clusters, HPX thread debugging, awareness of internal HPX data structures, and semi-automated preparation for distributed debugging sessions. Additional functionality such as locating an object and viewing the queue information on each core is provided through using API provided by HPX itself. His work can be found on GitHub.
Developing a better distributed debugging tool is essential to increase the programmability of HPX. Parsa’s project, Scimitar, aims to facilitate the debugging process for HPX programmers by extending the features of GDB, an existing debugger. The project then complements it with new commands for easier switching between localities across clusters, HPX thread debugging, awareness of internal HPX data structures, and semi-automated preparation for distributed debugging sessions. Additional functionality such as locating an object and viewing the queue information on each core is provided through using API provided by HPX itself. His work can be found on GitHub. This project aimed to expose a Map/Reduce programming model over HPX. During the summer, Aalekh was able to develop a single node implementation of HPXflow (map/reduce programming model) and laid the groundwork for the further multi-node version with database support. Although the initial task was limited to implementing the Map/Reduce model, he was also able to implement an improved dataflow model as well.
This project aimed to expose a Map/Reduce programming model over HPX. During the summer, Aalekh was able to develop a single node implementation of HPXflow (map/reduce programming model) and laid the groundwork for the further multi-node version with database support. Although the initial task was limited to implementing the Map/Reduce model, he was also able to implement an improved dataflow model as well. Minh-Khanh’s task was to take the parallel algorithms and add the functionality required to work on the segmented hpx::vector. Under his mentor John Biddscombe, he implemented the segmented_fill algorithm, which was successfully merged into the main codebase. Additionally, Minh-Khanh implemented the segmented_scan algorithm which includes inclusive and exclusive_scan. These changes are included in a pull request and have been merged. Using the segmented scan algorithm it is possible to perform tasks such as evaluating polynomials and to implement other algorithms such as quicksort.
Minh-Khanh’s task was to take the parallel algorithms and add the functionality required to work on the segmented hpx::vector. Under his mentor John Biddscombe, he implemented the segmented_fill algorithm, which was successfully merged into the main codebase. Additionally, Minh-Khanh implemented the segmented_scan algorithm which includes inclusive and exclusive_scan. These changes are included in a pull request and have been merged. Using the segmented scan algorithm it is possible to perform tasks such as evaluating polynomials and to implement other algorithms such as quicksort. In HPX, schedulers are statically linked and must be built at compile-time. Satyaki’s project involved converting this statically linked scheme into a plugin system which would allow arbitrary schedulers to be dynamically loaded. These changes bring several benefits. They provide a layer of abstraction and follow the open/closed principle of software design as well as allowing developers to write their own custom schedulers while conforming to a uniform API. The project proceeded in two steps. The first involved the creation of plugin modules of the schedulers and registering them with HPX. The second step was to implement the loading and subsequent use of the chosen scheduler.
In HPX, schedulers are statically linked and must be built at compile-time. Satyaki’s project involved converting this statically linked scheme into a plugin system which would allow arbitrary schedulers to be dynamically loaded. These changes bring several benefits. They provide a layer of abstraction and follow the open/closed principle of software design as well as allowing developers to write their own custom schedulers while conforming to a uniform API. The project proceeded in two steps. The first involved the creation of plugin modules of the schedulers and registering them with HPX. The second step was to implement the loading and subsequent use of the chosen scheduler.