Running your models in production with TensorFlow Serving
February 16th, 2016 | Published in Google Research
Machine learning powers many Google product features, from speech recognition in the Google app to Smart Reply in Inbox to search in Google Photos. While decades of experience have enabled the software industry to establish best practices for building and supporting products, doing so for services based upon machine learning introduces new and interesting challenges.
Today, we announce the release of TensorFlow Serving, designed to address some of these challenges. TensorFlow Serving is a high performance, open source serving system for machine learning models, designed for production environments and optimized for TensorFlow.
- model lifecycle management
- experiments with multiple algorithms
- efficient use of GPU resources
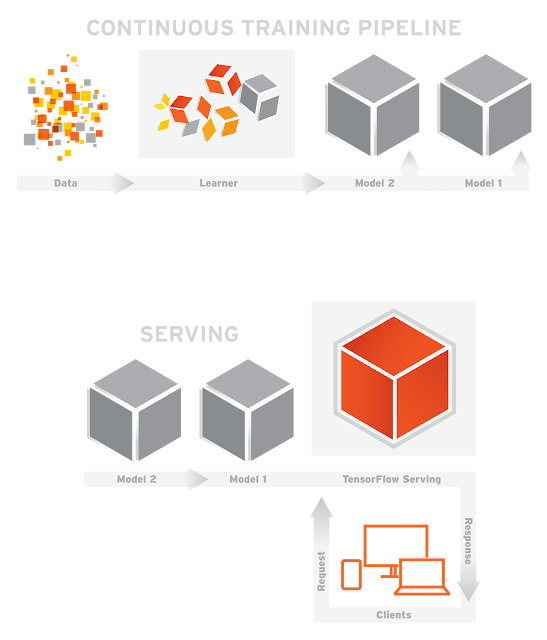
Here’s how it works. In the simplified, supervised training pipeline shown below, training data is fed to the learner, which outputs a model:

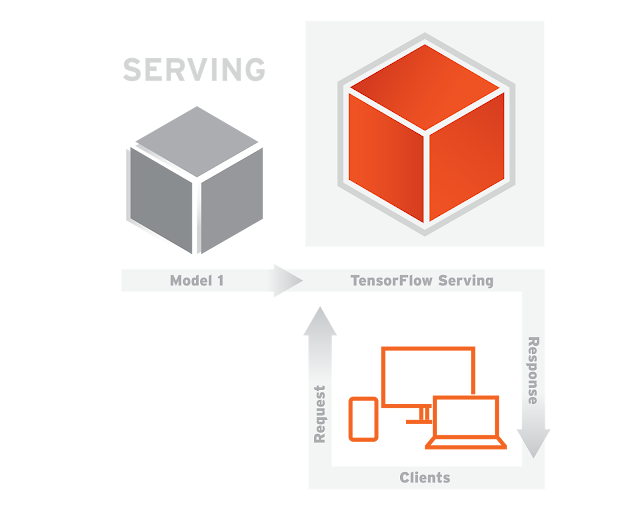
It is quite common to launch and iterate on your model over time, as new data becomes available, or as you improve the model. In fact, at Google, many pipelines run continuously, producing new model versions as new data becomes available.
We are excited to share this important component of TensorFlow today under the Apache 2.0 open source license. We would love to hear your questions and feature requests on Stack Overflow and GitHub respectively. To get started quickly, clone the code from github.com/tensorflow/serving and check out this tutorial.
You can expect to keep hearing more about TensorFlow as we continue to develop what we believe to be one of the best machine learning toolboxes in the world. If you'd like to stay up to date, follow @googleresearch or +ResearchatGoogle, and keep an eye out for Jeff Dean's keynote address at GCP Next 2016 in March.