On the Personalities of Dead Authors
February 24th, 2016 | Published in Google Research
“Great, ice cream for dinner!”
How would you interpret that? If a 6 year old says it, it feels very different than if a parent says it. People are good at inferring the deeper meaning of language based on both the context in which something was said, and their knowledge of the personality of the speaker.
But can one program a computer to understand the intended meaning from natural language in a way similar to us? Developing a system that knows definitions of words and rules of grammar is one thing, but giving a computer conversational context along with the expectations of a speaker’s behaviors and language patterns is quite another!
To tackle this challenge, a Natural Language Understanding research group, led by Ray Kurzweil, works on building systems able to understand natural language at a deeper level. By experimenting with systems able to perceive and project different personality types, it is our goal to enable computers to interpret the meaning of natural language similar to the way we do.
One way to explore this research is to build a system capable of sentence prediction. Can we build a system that can, given a sentence from a book and knowledge of the author’s style and “personality”, predict what the author is most likely to write next?
We started by utilizing the works of a thousand different authors found on Project Gutenberg to see if we could train a Deep Neural Network (DNN) to predict, given an input sentence, what sentence would come next. The idea was to see whether a DNN could - given millions of lines from a jumble of authors - “learn” a pattern or style that would lead one sentence to follow another.
This initial system had no author ID at the input - we just gave it pairs (line, following line) from 80% of the literary sample (saving 20% of it as a validation holdout). The labels at the output of the network are a simple YES or NO, depending on whether the example was truly a pair of sentences in sequence from the training data, or a randomly matched pair. This initial system had an error rate of 17.2%, where a random guess would be 50%. A slightly more sophisticated version also adds a fixed number of previous sentences for context, which decreased the error down to 12.8%.
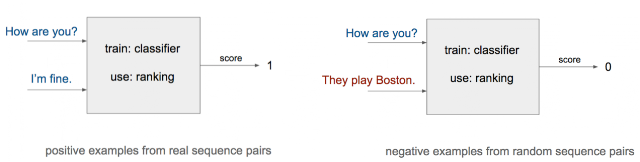
The 300 dimensional vectors our system derived to do these predictions are presumably representative of the Author’s word choice, thinking, and style. We call these “Author vectors”, analogous to word vectors or paragraph vectors. To get an intuitive sense of what these vectors are capturing, we projected the 300 dimensional space into two dimensions and plotted them as shown in the figure below. This gives some semblance of similarity and relative positions of authors in the space.
 |
| A two-dimensional representation of the vector embeddings for some of the authors in our study. To project the 300 dimensional vectors to two dimensions, we used the t-SNE algorithm. Note that contemporaries and influencers tend to be near each other (E.g., Nathaniel Hawthorne and Herman Melville, or Marlowe and Shakespeare). |
With this working, we wondered, “How would the model respond to the questions of a personality test?” But to simulate how different authors might respond to questions found in such tests, we needed a NN that, rather than strictly making a yes/no decision, would produce a yes/no decision while being influenced by the author vector - including sentences it hasn't seen before.
To simulate different authors’ responses to questions, we use the author vectors described above as inputs to our more general networks. In that way, we get the performance and generalization of the network across all authors and text it learned on, but influenced by what’s unique to a chosen author. Combined with our generative model, these vectors allow us to generate responses as different authors. In effect, one can chat with a statistical representation of the text written by Shakespeare!
Once we set the author vector for a chosen author, we posed the Myers Briggs questions to the system as the “current sentence”, set the author vector for the chosen author, and gave the Myers Briggs response options as the next-sentence candidates. When we asked “Are you more of”: “a private person” or “an outgoing person” to our model of Shakespeare’s texts, it predicted “a private person”. When we changed the author vector to Mark Twain and pose the same question, we got “an outgoing person”.

Though we can in no way claim that these models accurately respond with with the authors would have said, there are a few amusing anecdotes. When asked “Who is your favorite author?” and gave the options “Mark Twain”, “William Shakespeare”, “Myself”, and “Nobody”, the Twain model responded with “Mark Twain” and the Shakespeare model responded with “William Shakespeare”. Another example comes from the personality test: “When the phone rings” Shakespeare's model “hope[s] someone else will answer”, while Twain's “[tries] to get to it first”. Fitting, perhaps, since the telephone was patented during Twain's lifetime, but after Shakespeare.
This work is an early step towards better understanding intent, and how long-term context influences interpretation of text. In addition to being fun and interesting, this work has the potential to enrich products through personalization. For example, it could help provide more personalized response options for the recently introduced Smart Reply feature in Inbox by Gmail.