Learning the meaning behind words
August 14th, 2013 | Published in Google Open Source
Today computers aren't very good at understanding human language, and that forces people to do a lot of the heavy lifting—for example, speaking "searchese" to find information online, or slogging through lengthy forms to book a trip. Computers should understand natural language better, so people can interact with them more easily and get on with the interesting parts of life.
While state-of-the-art technology is still a ways from this goal, we’re making significant progress using the latest machine learning and natural language processing techniques. Deep learning has markedly improved speech recognition and image classification. For example, we’ve shown that computers can learn to recognize cats (and many other objects) just by observing large amount of images, without being trained explicitly on what a cat looks like. Now we apply neural networks to understanding words by having them “read” vast quantities of text on the web. We’re scaling this approach to datasets thousands of times larger than what has been possible before, and we’ve seen a dramatic improvement of performance -- but we think it could be even better. To promote research on how machine learning can apply to natural language problems, we’re publishing an open source toolkit called word2vec that aims to learn the meaning behind words.
Word2vec uses distributed representations of text to capture similarities among concepts. For example, it understands that Paris and France are related the same way Berlin and Germany are (capital and country), and not the same way Madrid and Italy are. This chart shows how well it can learn the concept of capital cities, just by reading lots of news articles -- with no human supervision:
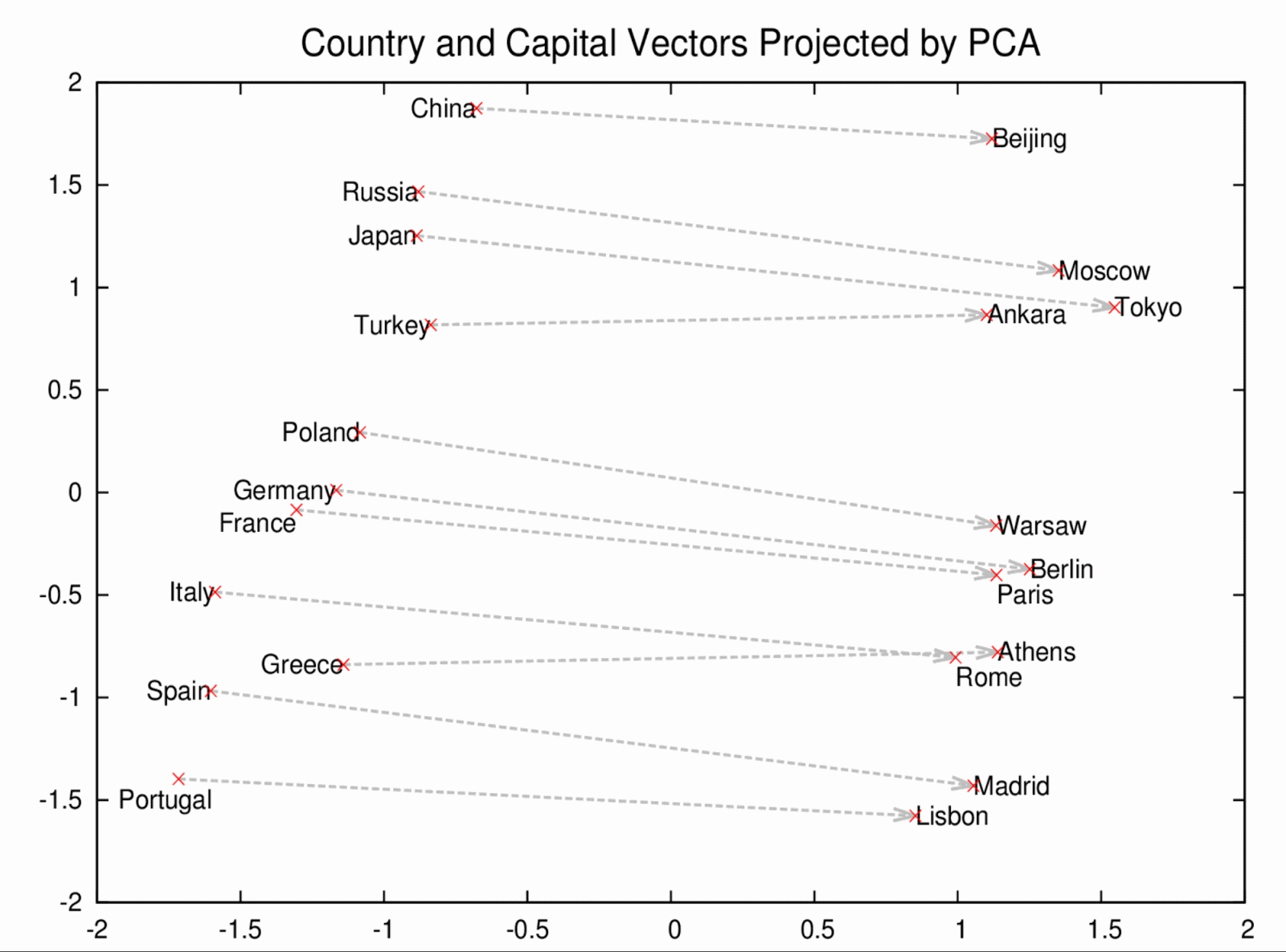
The model not only places similar countries next to each other, but also arranges their capital cities in parallel. The most interesting part is that we didn’t provide any supervised information before or during training. Many more patterns like this arise automatically in training.
This has a very broad range of potential applications: knowledge representation and extraction; machine translation; question answering; conversational systems; and many others. We’re open sourcing the code for computing these text representations efficiently (on even a single machine) so the research community can take these models further.
We hope this helps connect researchers on machine learning, artificial intelligence, and natural language so they can create amazing real-world applications.
By Tomas Mikolov, Ilya Sutskever, and Quoc Le, Google Knowledge
While state-of-the-art technology is still a ways from this goal, we’re making significant progress using the latest machine learning and natural language processing techniques. Deep learning has markedly improved speech recognition and image classification. For example, we’ve shown that computers can learn to recognize cats (and many other objects) just by observing large amount of images, without being trained explicitly on what a cat looks like. Now we apply neural networks to understanding words by having them “read” vast quantities of text on the web. We’re scaling this approach to datasets thousands of times larger than what has been possible before, and we’ve seen a dramatic improvement of performance -- but we think it could be even better. To promote research on how machine learning can apply to natural language problems, we’re publishing an open source toolkit called word2vec that aims to learn the meaning behind words.
Word2vec uses distributed representations of text to capture similarities among concepts. For example, it understands that Paris and France are related the same way Berlin and Germany are (capital and country), and not the same way Madrid and Italy are. This chart shows how well it can learn the concept of capital cities, just by reading lots of news articles -- with no human supervision:
The model not only places similar countries next to each other, but also arranges their capital cities in parallel. The most interesting part is that we didn’t provide any supervised information before or during training. Many more patterns like this arise automatically in training.
This has a very broad range of potential applications: knowledge representation and extraction; machine translation; question answering; conversational systems; and many others. We’re open sourcing the code for computing these text representations efficiently (on even a single machine) so the research community can take these models further.
We hope this helps connect researchers on machine learning, artificial intelligence, and natural language so they can create amazing real-world applications.
By Tomas Mikolov, Ilya Sutskever, and Quoc Le, Google Knowledge