What’s different about the new Google Docs: Working together, even apart
September 21st, 2010 | Published in Google Docs
Editor’s Note: In May, we walked through some technical details about what’s different in the new Google Docs. Beginning today, we’ll dive into the collaboration technology behind Google Docs in three parts, starting with a look at the challenges encountered when building a collaborative application. Tomorrow’s post will describe how Google Docs uses an algorithm called operational transformation to merge edits in real time. Finally, on Thursday, we’ll dive into the collaboration protocol for sending changes between the editors.
The way people work is changing. Ten years ago, it was too hard to co-author a document, so things took longer, or people just put up with less collaboration. But as our communication tools have become better, it’s become more common to have a group of people writing a doc collaboratively.
Collaboration is technically difficult because many people can be making changes to the same content at almost the same time. Since connection speeds aren’t instantaneous, when you make a change, you’re temporarily creating a local version of the document that is different from the versions other collaborators see. The core implementation challenge is to make sure that all the editing sessions eventually converge on the same, correct, version of the document.
One approach taken by the old Google documents and by many other collaborative word processors is to compare document versions. Suppose there are two editors: John and Luiz. In the old Google Docs, the server begins with one version of a document and receives an updated version from John. The server finds the differences between its version and John’s version and decides out how to merge those two versions as best it can. Then the server sends this merged version to Luiz. If Luiz has changes that have not yet been sent to the server, then he needs to compare the server version with his local version and merge the two versions together. Then Luiz sends this merged local version to the server and the process continues.
But often, this approach doesn’t work well. Take the example below. John, Luiz and the server start with the text The quick brown fox. John bolds the words brown fox. As he’s doing this, Luiz highlights the word fox and replaces it with the word dog. Suppose John’s changes arrive at the server first, and then the server sends those changes to Luiz.
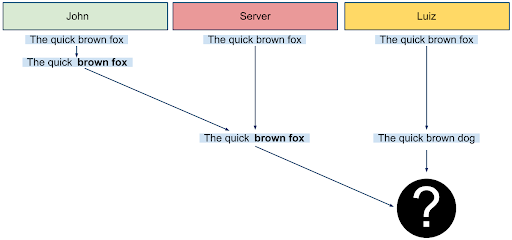
The correct way to merge John’s style change and Luiz’s text substitution is as The quick brown dog. But Luiz doesn’t have enough information to know what the correct merge is. From his perspective, The quick brown fox dog, The quick brown dog, The quick brown dog fox are all perfectly valid ways of merging the two versions. And that’s the problem: if you just compare versions, you can’t make sure that changes are merged in the way that an editor would expect.
You can avoid the merging problem by introducing more restrictions on the editors. For example, you could lock paragraphs so that only one editor was ever allowed to type in a single paragraph at a given time. But locking paragraphs isn’t a great solution: you’re sidestepping the technical challenges by hampering the collaborative editing experience. Plus, it’s always possible for two editors to begin editing a paragraph at the same time. In that case, one of the editors will find out that he didn’t actually acquire the paragraph lock and any changes that he made while he thought he had the lock will need to be merged (which has all of the above problems) or discarded.
The new version of Google documents does things differently. In the new editor, a document is stored as a series of chronological changes. A change might be something like {InsertText 'T' @10}. That particular change was to insert the letter T at the 10th position in the document. A fundamental difference between the new editor and the old one is that instead of computing the changes by comparing document versions, we now compute the versions by playing forward the history of changes.
This approach creates a better collaboration experience, because the editors’ intentions are never ambiguous. Since we know the revision of each change, we can check what the editor saw when he made that change and we can figure out how to correctly merge that change with any changes that were made since then.
That’s it for today. Tomorrow’s post will give an overview of the algorithm for merging changes — operational transformation. Even if we know how to properly merge changes, we still need to make sure that each editor knows when there are changes that need to be merged. This challenge is handled by the collaboration protocol which will be the subject of Thursday’s post. Together, these technologies create the character-by-character collaboration in Google Docs.
The way people work is changing. Ten years ago, it was too hard to co-author a document, so things took longer, or people just put up with less collaboration. But as our communication tools have become better, it’s become more common to have a group of people writing a doc collaboratively.
Collaboration is technically difficult because many people can be making changes to the same content at almost the same time. Since connection speeds aren’t instantaneous, when you make a change, you’re temporarily creating a local version of the document that is different from the versions other collaborators see. The core implementation challenge is to make sure that all the editing sessions eventually converge on the same, correct, version of the document.
One approach taken by the old Google documents and by many other collaborative word processors is to compare document versions. Suppose there are two editors: John and Luiz. In the old Google Docs, the server begins with one version of a document and receives an updated version from John. The server finds the differences between its version and John’s version and decides out how to merge those two versions as best it can. Then the server sends this merged version to Luiz. If Luiz has changes that have not yet been sent to the server, then he needs to compare the server version with his local version and merge the two versions together. Then Luiz sends this merged local version to the server and the process continues.
But often, this approach doesn’t work well. Take the example below. John, Luiz and the server start with the text The quick brown fox. John bolds the words brown fox. As he’s doing this, Luiz highlights the word fox and replaces it with the word dog. Suppose John’s changes arrive at the server first, and then the server sends those changes to Luiz.
The correct way to merge John’s style change and Luiz’s text substitution is as The quick brown dog. But Luiz doesn’t have enough information to know what the correct merge is. From his perspective, The quick brown fox dog, The quick brown dog, The quick brown dog fox are all perfectly valid ways of merging the two versions. And that’s the problem: if you just compare versions, you can’t make sure that changes are merged in the way that an editor would expect.
You can avoid the merging problem by introducing more restrictions on the editors. For example, you could lock paragraphs so that only one editor was ever allowed to type in a single paragraph at a given time. But locking paragraphs isn’t a great solution: you’re sidestepping the technical challenges by hampering the collaborative editing experience. Plus, it’s always possible for two editors to begin editing a paragraph at the same time. In that case, one of the editors will find out that he didn’t actually acquire the paragraph lock and any changes that he made while he thought he had the lock will need to be merged (which has all of the above problems) or discarded.
The new version of Google documents does things differently. In the new editor, a document is stored as a series of chronological changes. A change might be something like {InsertText 'T' @10}. That particular change was to insert the letter T at the 10th position in the document. A fundamental difference between the new editor and the old one is that instead of computing the changes by comparing document versions, we now compute the versions by playing forward the history of changes.
This approach creates a better collaboration experience, because the editors’ intentions are never ambiguous. Since we know the revision of each change, we can check what the editor saw when he made that change and we can figure out how to correctly merge that change with any changes that were made since then.
That’s it for today. Tomorrow’s post will give an overview of the algorithm for merging changes — operational transformation. Even if we know how to properly merge changes, we still need to make sure that each editor knows when there are changes that need to be merged. This challenge is handled by the collaboration protocol which will be the subject of Thursday’s post. Together, these technologies create the character-by-character collaboration in Google Docs.