What’s different about the new Google Docs: Making collaboration fast
September 23rd, 2010 | Published in Google Docs
This is the final post in a three part series about the collaboration technology in Google Docs. On Tuesday, we explained some of the technical challenges behind real time collaboration. Yesterday, we showed how operational transformation can be used merge editors’ changes.
Imagine that you’re doing a jigsaw puzzle with a bunch of friends and that everyone is working in the same corner of the puzzle. It’s possible to solve a puzzle like this, but it’s hard to keep out of each other’s way and to make sure that when multiple pieces are added at once, that they all fit together perfectly. Making a document collaborative is a little like that: one challenge is coming up with a method to let multiple people edit in the same area without conflicting edits. A second problem is to ensure that when many changes happen at the same time, each change is merged properly with each other changes. In Google Docs, the first problem is handled by operational transformation and the second problem is handled by the collaboration protocol, which is the subject of this post.
To open a Google document, you need code running in two places: your browser and our servers. We call the code that’s running in your browser a client. In the document editor, the client processes all your edits, sends them to the server, and processes other editors’ changes when it receives them from the server.
To collaborate in Google Docs, each client keeps track of four pieces of information:
In the diagrams below, the two outer columns represent the editors: Luiz and John. The middle column is the server. The oval shapes represent changes inputted by the editors and sent between the clients and the server. The diamonds represent transformations.
Let’s say Luiz starts by typing the word Hello at the beginning of the document.

Luiz’s client added the edit to his list of pending changes. He then sent the change to the server and moved the change into his list of sent changes.
Luiz continues to type, adding the word world to his document. At the same time, John types an ! in his empty version of the document (remember he has not yet received Luiz’s first change).

Luiz’s {InsertText ' world' @6} change was placed in the pending list and wasn’t sent to the server because we never send more than one pending change at a time. Until Luiz recieves an acknowledgement of his first change, his client will keep all new changes in the pending list. Also notice that the server stored Luiz’s first change in its revision log. Next, the server will send John a message containing Luiz’s first change and it will send Luiz a message acknowledging that it has processed that first change.

John received Luiz’s edit from the server and used operational transformation (OT) to transform it against his pending {InsertText '!' @1} change. The result of the transformation was to shift the location of John’s pending change by 5 to make room at the beginning of the document for Luiz’s Hello. Notice that both Luiz and John updated their last synced revision numbers to 1 when they received the messages from the server. Lastly, when Luiz received the acknowledgement of his first change, he removed that first change from the list of sent changes.
Next, both Luiz and John are going to send their unsent changes to the server.
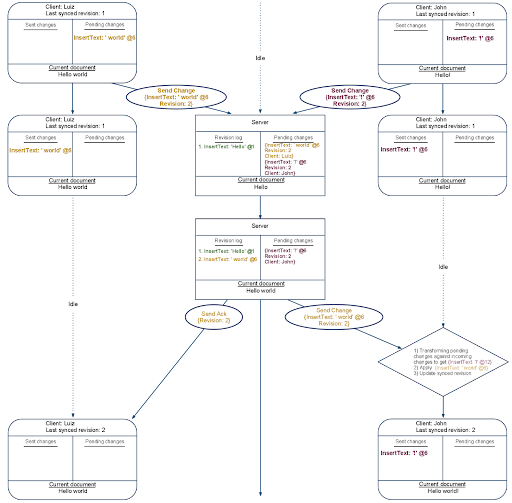
The server got Luiz’s change before John’s so it processed that change first. An acknowledgement of the change was sent to Luiz. The change itself was sent to John, where his client transformed it against his still pending {InsertText '!' @1} change.
What comes next is important. The server received John’s pending change, a change that John believes should be Revision 2. But the server has already committed a Revision 2 to the revision log. The server will use OT to transform John’s change so that it can be stored as Revision 3.

The first thing the server did, was to transform John’s sent change against all the changes that have been committed since the last time John synced with the server. In this case, it transformed John’s change against Luiz’s {InsertText ' world' @6}. The result shifted the index of John’s change over by 6. This shift is identical to the transformation John’s client made when it first received Luiz’s {InsertText 'Hello' @1}.
The example above ends with Luiz and John receiving John’s change and the acknowledgement of that change respectively. At this point the server and both editors are looking at the same document — Hello world!.
The main advantages of this collaboration protocol are:
Well that’s all folks: we hope by reading this series you learned a bit more about what’s under the hood in Google Docs, and the kinds of things you need to think about to make a fast collaboration experience. You can try collaboration yourself, without signing in, by visiting the Google Docs demo.
Imagine that you’re doing a jigsaw puzzle with a bunch of friends and that everyone is working in the same corner of the puzzle. It’s possible to solve a puzzle like this, but it’s hard to keep out of each other’s way and to make sure that when multiple pieces are added at once, that they all fit together perfectly. Making a document collaborative is a little like that: one challenge is coming up with a method to let multiple people edit in the same area without conflicting edits. A second problem is to ensure that when many changes happen at the same time, each change is merged properly with each other changes. In Google Docs, the first problem is handled by operational transformation and the second problem is handled by the collaboration protocol, which is the subject of this post.
To open a Google document, you need code running in two places: your browser and our servers. We call the code that’s running in your browser a client. In the document editor, the client processes all your edits, sends them to the server, and processes other editors’ changes when it receives them from the server.
To collaborate in Google Docs, each client keeps track of four pieces of information:
- The number of the most recent revision sent from the server to the client.
- Any changes that have been made locally and not yet sent to the server.
- Any changes that have been made locally, sent to the server, but not yet acknowledged by the server.
- The current state of the document as seen by that particular editor.
- The list of all changes that it has received but not yet processed.
- The complete history of all processed changes (called the revision log)./li>
- The current state of the document as of the last processed change./li>
In the diagrams below, the two outer columns represent the editors: Luiz and John. The middle column is the server. The oval shapes represent changes inputted by the editors and sent between the clients and the server. The diamonds represent transformations.
Let’s say Luiz starts by typing the word Hello at the beginning of the document.
Luiz’s client added the edit to his list of pending changes. He then sent the change to the server and moved the change into his list of sent changes.
Luiz continues to type, adding the word world to his document. At the same time, John types an ! in his empty version of the document (remember he has not yet received Luiz’s first change).
Luiz’s {InsertText ' world' @6} change was placed in the pending list and wasn’t sent to the server because we never send more than one pending change at a time. Until Luiz recieves an acknowledgement of his first change, his client will keep all new changes in the pending list. Also notice that the server stored Luiz’s first change in its revision log. Next, the server will send John a message containing Luiz’s first change and it will send Luiz a message acknowledging that it has processed that first change.
John received Luiz’s edit from the server and used operational transformation (OT) to transform it against his pending {InsertText '!' @1} change. The result of the transformation was to shift the location of John’s pending change by 5 to make room at the beginning of the document for Luiz’s Hello. Notice that both Luiz and John updated their last synced revision numbers to 1 when they received the messages from the server. Lastly, when Luiz received the acknowledgement of his first change, he removed that first change from the list of sent changes.
Next, both Luiz and John are going to send their unsent changes to the server.
The server got Luiz’s change before John’s so it processed that change first. An acknowledgement of the change was sent to Luiz. The change itself was sent to John, where his client transformed it against his still pending {InsertText '!' @1} change.
What comes next is important. The server received John’s pending change, a change that John believes should be Revision 2. But the server has already committed a Revision 2 to the revision log. The server will use OT to transform John’s change so that it can be stored as Revision 3.
The first thing the server did, was to transform John’s sent change against all the changes that have been committed since the last time John synced with the server. In this case, it transformed John’s change against Luiz’s {InsertText ' world' @6}. The result shifted the index of John’s change over by 6. This shift is identical to the transformation John’s client made when it first received Luiz’s {InsertText 'Hello' @1}.
The example above ends with Luiz and John receiving John’s change and the acknowledgement of that change respectively. At this point the server and both editors are looking at the same document — Hello world!.
The main advantages of this collaboration protocol are:
- Collaboration is fast. At all times, every editor can optimistically apply their own changes locally without waiting for the server to acknowledge those changes. This means that the speed or reliability of your network connection doesn’t influence how fast you can type.
- Collaboration is accurate. There is always enough information for each client to merge collaborators’ changes in the same deterministic way.
- Collaboration is efficient. The information that is sent over the network is always the bare minimum needed to describe what changed.
- Collaboration complexity is constant. The server does not need to know anything about the state of each client. Therefore, the complexity of processing changes does not increase as you add more editors.
- Collaboration is distributed. Only the server needs to be aware of the document’s history and only the clients need to be aware of uncommitted changes. This division spreads the workload required to support real time collaboration between all the parties involved.
Well that’s all folks: we hope by reading this series you learned a bit more about what’s under the hood in Google Docs, and the kinds of things you need to think about to make a fast collaboration experience. You can try collaboration yourself, without signing in, by visiting the Google Docs demo.