Conference Data Sync and GCM in the Google I/O App
September 10th, 2014 | Published in Google Android
Keeping data in sync with the cloud is an important part of many applications, and the Google I/O App is no exception. To do this, we leverage the standard Android mechanism for this purpose: a Sync Adapter. Using a Sync Adapter has many benefits over using a more rudimentary mechanism such as setting up recurring alarms, because the system automatically handles the scheduling of Sync Adapters to optimize battery life.
We store the data in a local SQLite database. However, rather than having the whole application access that database directly, the application employs another standard Android mechanism to control and organize access to that data. This structure is, naturally, a Content Provider. Only the content provider's implementation has direct access to the SQLite database. All other parts of the app can only access data through the Content Resolver. This allows for a very flexible decoupling between the representation of the data in the database and the more abstract view of that data that is used throughout the app.
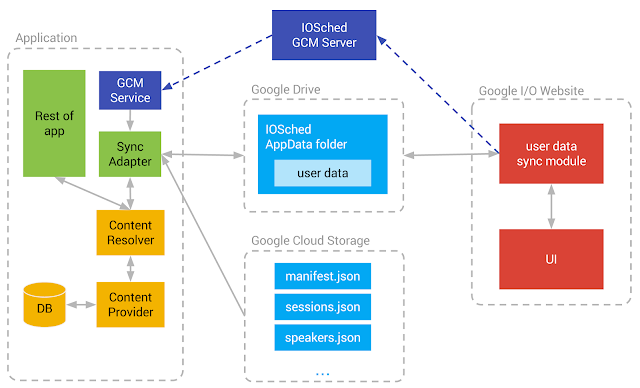
The I/O app maintains with two main kinds of data: conference data (sessions, speakers, rooms, etc) and user data (the user's personalized schedule). Conference data is kept up to date with a one-way sync from a set of JSON files stored in Google Cloud Storage, whereas user data goes through a two-way sync with a file stored in the user's Google Drive AppData folder.
Downloading Conference Data Efficiently
For a conference like Google I/O, conference data can be somewhat large. It consists of information about all the sessions, rooms, speakers, map locations, social hashtags, video library items and others. Downloading the whole data set repeatedly would be wasteful both in terms of battery and bandwidth, so we adopt a strategy to minimize the amount of data we download and process.
This strategy is separating the data into several different JSON files, and having them be referenced by a central master JSON file called the manifest file. The URL of the manifest file is the only URL that is hard-coded into the app (it is defined by the MANIFEST_URL constant in Config.java). Note that the I/O app uses Google Cloud Storage to store and serve these files, but any robust hosting service accessible via HTTP can be used for the same purpose.
The first part of the sync process is checking if the manifest file was changed since the app last downloaded it, and processing it only if it's newer. This logic is implemented by the fetchConfenceDataIfNewer method in RemoteConferenceDataFetcher.
public class RemoteConferenceDataFetcher {
// (...)
public String[] fetchConferenceDataIfNewer(String refTimestamp) throws IOException {
BasicHttpClient httpClient = new BasicHttpClient();
httpClient.setRequestLogger(mQuietLogger);
// (...)
// Only download if data is newer than refTimestamp
if (!TextUtils.isEmpty(refTimestamp) && TimeUtils
.isValidFormatForIfModifiedSinceHeader(refTimestamp)) {
httpClient.addHeader("If-Modified-Since", refTimestamp);
}
}
HttpResponse response = httpClient.get(mManifestUrl, null);
int status = response.getStatus();
if (status == HttpURLConnection.HTTP_OK) {
// Data modified since we last checked -- process it!
} else if (status == HttpURLConnection.HTTP_NOT_MODIFIED) {
// data on the server is not newer than our data - no work to do!
return null;
} else {
// (handle error)
}
}
// (...)
}
Notice that we submit the HTTP If-Modified-Since header with our request, so that if the manifest hasn't changed since we last checked it, we will get an HTTP response code of HTTP_NOT_MODIFIED rather than HTTP_OK, we will react by skipping the download and parsing process. This means that unless the manifest has changed since we last saw it, the sync process is very economical: it consists only of a single HTTP request and a short response.
The manifest file's format is straightforward: it consists of references to other JSON files that contain the relevant pieces of the conference data:
{
"format": "iosched-json-v1",
"data_files": [
"past_io_videolibrary_v5.json",
"experts_v11.json",
"hashtags_v8.json",
"blocks_v10.json",
"map_v11.json",
"keynote_v10.json",
"partners_v2.json",
"session_data_v2.681.json"
]
}
The sync process then proceeds to process each of the listed data files in order. This part is also implemented to be as economical as possible: if we detect that we already have a cached version of a specific data file, we skip it entirely and use our local cache instead. This task is done by the processManifest method.
Then, each JSON file is parsed and the entities present in each one are accumulated in memory. At the end of this process, the data is written to the Content Provider.
Issuing Content Provider Operations Efficiently
The conference data sync needs to be efficient not only in the amount of data it downloads, but also in the amount of operations it performs on the database. This must be done as economically as possible, so this step is also optimized: instead of overwriting the whole database with the new data, the Sync Adapter attempts to preserve the existing entities and only update the ones that have changed. In our tests, this optimization step reduced the total sync time from 16 seconds to around 2 seconds on our test devices.
In order to accomplish this important third layer of optimization, the application needs to know, given an entity in memory and its version in the Content Provider, whether or not we need to issue content provider operations to update that entity. Comparing the entity in memory to the entity in the database field by field is one option, but is cumbersome and slow, since it would require us to read every field. Instead, we add a field to each entity called the import hashcode. The import hashcode is a weak hash value generated from its data. For example, here is how the import hashcode for a speaker is computed:
public class Speaker {
public String id;
public String publicPlusId;
public String bio;
public String name;
public String company;
public String plusoneUrl;
public String thumbnailUrl;
public String getImportHashcode() {
StringBuilder sb = new StringBuilder();
sb.append("id").append(id == null ? "" : id)
.append("publicPlusId")
.append(publicPlusId == null ? "" : publicPlusId)
.append("bio")
.append(bio == null ? "" : bio)
.append("name")
.append(name == null ? "" : name)
.append("company")
.append(company== null ? "" : company)
.append("plusoneUrl")
.append(plusoneUrl == null ? "" : plusoneUrl)
.append("thumbnailUrl")
.append(thumbnailUrl == null ? "" : thumbnailUrl);
String result = sb.toString();
return String.format(Locale.US, "%08x%08x",
result.hashCode(), result.length());
}
}
Every time an entity is updated in the database, its import hashcode is saved with it as a database column. Later, when we have a candidate for an updated version of that entity, all we need to do is compute the import hashcode of the candidate and compare it to the import hashcode of the entity in the database. If they differ, then we issue Content Provider operations to update the entity in the database. If they are the same, we skip that entity. This incremental update logic can be seen, for example, in the makeContentProviderOperations method of the SpeakersHandler class:
public class SpeakersHandler extends JSONHandler {
private HashMap mSpeakers = new HashMap();
// (...)
@Override
public void makeContentProviderOperations(ArrayList list) {
// (...)
int updatedSpeakers = 0;
for (Speaker speaker : mSpeakers.values()) {
String hashCode = speaker.getImportHashcode();
speakersToKeep.add(speaker.id);
if (!isIncrementalUpdate || !speakerHashcodes.containsKey(speaker.id) ||
!speakerHashcodes.get(speaker.id).equals(hashCode)) {
// speaker is new/updated, so issue content provider operations
++updatedSpeakers;
boolean isNew = !isIncrementalUpdate ||
!speakerHashcodes.containsKey(speaker.id);
buildSpeaker(isNew, speaker, list);
}
}
// delete obsolete speakers
int deletedSpeakers = 0;
if (isIncrementalUpdate) {
for (String speakerId : speakerHashcodes.keySet()) {
if (!speakersToKeep.contains(speakerId)) {
buildDeleteOperation(speakerId, list);
++deletedSpeakers;
}
}
}
}
}
The buildSpeaker and buildDeleteOperation methods (omitted here for brevity) simply build the Content Provider operations necessary to, respectively, insert/update a speaker or delete a speaker from the Content Provider. Notice that this approach means we only issue Content Provider operations to update a speaker if the import hashcode has changed. We also deal with obsolete speakers, that is, speakers that were in the database but were not referenced by the incoming data, and we issue delete operations for those speakers.
Making Sync Robust
The sync adapter in the I/O app is responsible for several tasks, amongst which are the remote conference data sync, the user schedule sync and also the user feedback sync. Failures can happen in any of them because of network conditions and other factors. However, a failure in one of the tasks should not impact the execution of the other tasks. This is why we structure the sync process as a series of independent tasks, each protected by a try/catch block, as can be seen in the performSync method of the SyncHelper class:
// remote sync consists of these operations, which we try one by one (and
// tolerate individual failures on each)
final int OP_REMOTE_SYNC = 0;
final int OP_USER_SCHEDULE_SYNC = 1;
final int OP_USER_FEEDBACK_SYNC = 2;
int[] opsToPerform = userDataOnly ?
new int[] { OP_USER_SCHEDULE_SYNC } :
new int[] { OP_REMOTE_SYNC, OP_USER_SCHEDULE_SYNC, OP_USER_FEEDBACK_SYNC};
for (int op : opsToPerform) {
try {
switch (op) {
case OP_REMOTE_SYNC:
dataChanged |= doRemoteSync();
break;
case OP_USER_SCHEDULE_SYNC:
dataChanged |= doUserScheduleSync(account.name);
break;
case OP_USER_FEEDBACK_SYNC:
doUserFeedbackSync();
break;
}
} catch (AuthException ex) {
// (... handle auth error...)
} catch (Throwable throwable) {
// (... handle other error...)
// Let system know an exception happened:
if (syncResult != null && syncResult.stats != null) {
++syncResult.stats.numIoExceptions;
}
}
}
When one particular part of the sync process fails, we let the system know about it by increasing syncResult.stats.numIoExceptions. This will cause the system to retry the sync at a later time, using exponential backoff.
When Should We Sync? Enter GCM.
It's very important for users to be able to get updates about conference data in a timely manner, especially during (and in the few days leading up to) Google I/O. A naïve way to solve this problem is simply making the app poll the server repeatedly for updates. Naturally, this causes problems with bandwidth and battery consumption.
To solve this problem in a more elegant way, we use GCM (Google Cloud Messaging). Whenever there is an update to the data on the server side, the server sends a GCM message to all registered devices. Upon receipt of this GCM message, the device performs a sync to download the new conference data. The GCMIntentService class handles the incoming GCM messages:
Update (23 September 2014): Since this blog post was first published, the GCMBaseIntentService class has been deprecated. Please use the GoogleCloudMessaging API instead.
public class GCMIntentService extends GCMBaseIntentService {
private static final String TAG = makeLogTag("GCM");
private static final Map MESSAGE_RECEIVERS;
static {
// Known messages and their GCM message receivers
Map receivers = new HashMap();
receivers.put("test", new TestCommand());
receivers.put("announcement", new AnnouncementCommand());
receivers.put("sync_schedule", new SyncCommand());
receivers.put("sync_user", new SyncUserCommand());
receivers.put("notification", new NotificationCommand());
MESSAGE_RECEIVERS = Collections.unmodifiableMap(receivers);
}
// (...)
@Override
protected void onMessage(Context context, Intent intent) {
String action = intent.getStringExtra("action");
String extraData = intent.getStringExtra("extraData");
LOGD(TAG, "Got GCM message, action=" + action + ", extraData=" + extraData);
if (action == null) {
LOGE(TAG, "Message received without command action");
return;
}
action = action.toLowerCase();
GCMCommand command = MESSAGE_RECEIVERS.get(action);
if (command == null) {
LOGE(TAG, "Unknown command received: " + action);
} else {
command.execute(this, action, extraData);
}
}
// (...)
}
Notice that the onMessage method delivers the message to the appropriate handler depending on the GCM message's "action" field. If the action field is "sync_schedule", the application delivers the message to an instance of the SyncCommand class, which causes a sync to happen. Incidentally, notice that the implementation of the SyncCommand class allows the GCM message to specify a jitter parameter, which causes it to trigger a sync not immediately but at a random time in the future within the jitter interval. This spreads out the syncs evenly over a period of time rather than forcing all clients to sync simultaneously, and thus prevents a sudden peak in requests on the server side.
Syncing User Data

The I/O app allows the user to build their own personalized schedule by choosing which sessions they are interested in attending. This data must be shared across the user's Android devices, and also between the I/O website and Android. This means this data has to be stored in the cloud, in the user's Google account. We chose to use the Google Drive AppData folder for this task.
User data is synced to Google Drive by the doUserScheduleSync method of the SyncHelper class. If you dive into the source code, you will notice that this method essentially accesses the Google Drive AppData folder through the Google Drive HTTP API, then reconciles the set of sessions in the data with the set of sessions starred by the user on the device, and issues the necessary modifications to the cloud if there are locally updated sessions.
This means that if the user selects one session on their Android device and then selects another session on the I/O website, the result should be that both the Android device and the I/O website will show that both sessions are in the user's schedule.
Also, whenever the user adds or removes a session on the I/O website, the data on all their Android devices should be updated, and vice versa. To accomplish that, the I/O website sends our GCM server a notification every time the user makes a change to their schedule; the GCM server, in turn, sends a GCM message to all the devices owned by that user in order to cause them to sync their user data. The same mechanism works across the user's devices as well: when one device updates the data, it issues a GCM message to all other devices.
Conclusion
Serving fresh data is a key component of many Android apps. This article showed how the I/O app deals with the challenges of keeping the data up-to-date while minimizing network traffic and database changes, and also keeping this data in sync across different platforms and devices through the use of Google Cloud Storage, Google Drive and Google Cloud Messaging.