By: Patrik Höglund
What is Automatic Gain Control?
It’s time to talk about advanced media quality tests again! As experienced Google testing blog readers know, when I write an article it’s usually about WebRTC, and the unusual testing solutions we build to test it. This article is no exception. Today we’re going to talk about Automatic Gain Control, or AGC. This is a feature that’s on by default for WebRTC applications, such as http://apprtc.appspot.com. It uses various means to adjust the microphone signal so your voice makes it loud and clear to the other side of the peer connection. For instance, it can attempt to adjust your microphone gain or try to amplify the signal digitally.
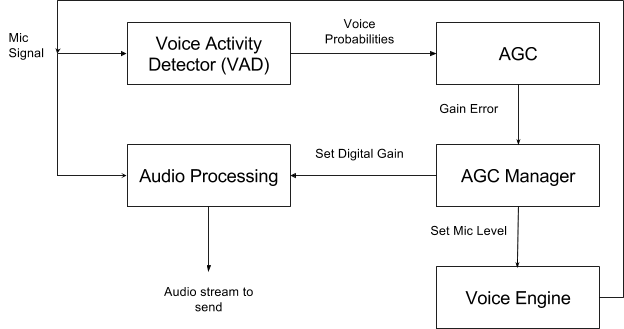
Figure 1. How Auto Gain Control works [code here].
This is an example of automatic control engineering (another example would be the classic PID controller) and happens in real time. Therefore, if you move closer to the mic while speaking, the AGC will notice the output stream is too loud, and reduce mic volume and/or digital gain. When you move further away, it tries to adapt up again. The fancy voice activity detector is there so we only amplify speech, and not, say, the microwave oven your spouse just started in the other room.
Testing the AGC
Now, how do we make sure the AGC works? The first thing is obviously to write unit tests and integration tests. You didn’t think about building that end-to-end test first, did you? Once we have the lower-level tests in place, we can start looking at a bigger test. While developing the WebRTC implementation in Chrome, we had several bugs where the AGC code was working by itself, but was misconfigured in Chrome. In one case, it was simply turned off for all users. In another, it was only turned off in Hangouts.
Only an end-to-end test can catch these integration issues, and we already had stable, low-maintenance audio quality tests with the ability to record Chrome’s output sound for analysis. I encourage you to read that article, but the bottom line is that those tests can run a WebRTC call in two tabs and record the audio output to a file. Those tests run the PESQ algorithm on input and output to see how similar they are.
That’s a good framework to have, but I needed to make two changes:
- Add file support to Chrome’s fake audio input device, so we can play a known file. The original audio test avoided this by using WebAudio, but AGC doesn’t run in the WebAudio path, just the microphone capture path, so that won’t work.
- Instead of running PESQ, run an analysis that compares the gain between input and output.
Adding Fake File Support
This is always a big part of the work in media testing: controlling the input and output. It’s unworkable to tape microphones to loudspeakers or point cameras to screens to capture the media, so the easiest solution is usually to add a debug flag. It is exactly what I did here. It was a lot of work, but I won’t go into much detail since Chrome’s audio pipeline is complex. The core is this:
int FileSource::OnMoreData(AudioBus* audio_bus, uint32 total_bytes_delay) {
// Load the file if we haven't already. This load needs to happen on the
// audio thread, otherwise we'll run on the UI thread on Mac for instance.
// This will massively delay the first OnMoreData, but we'll catch up.
if (!wav_audio_handler_)
LoadWavFile(path_to_wav_file_);
if (load_failed_)
return 0;
DCHECK(wav_audio_handler_.get());
// Stop playing if we've played out the whole file.
if (wav_audio_handler_->AtEnd(wav_file_read_pos_))
return 0;
// This pulls data from ProvideInput.
file_audio_converter_->Convert(audio_bus);
return audio_bus->frames();
}
This code runs every 10 ms and reads a small chunk from the file, converts it to Chrome’s preferred audio format and sends it on through the audio pipeline. After implementing this, I could simply run:
chrome --use-fake-device-for-media-stream
--use-file-for-fake-audio-capture=/tmp/file.wav
and whenever I hit a webpage that used WebRTC, the above file would play instead of my microphone input. Sweet!
The Analysis Stage
Next I had to get the analysis stage figured out. It turned out there was something called an AudioPowerMonitor in the Chrome code, which you feed audio data into and get the average audio power for the data you fed in. This is a measure of how “loud” the audio is. Since the whole point of the AGC is getting to the right audio power level, we’re looking to compute
Adiff = Aout – Ain
Or, really, how much louder or weaker is the output compared to the input audio? Then we can construct different scenarios: Adiff should be 0 if the AGC is turned off and it should be > 0 dB if the AGC is on and we feed in a low power audio file. Computing the average energy of an audio file was straightforward to implement:
// ...
size_t bytes_written;
wav_audio_handler->CopyTo(audio_bus.get(), 0, &bytes_written);
CHECK_EQ(bytes_written, wav_audio_handler->data().size())
"Expected to write entire file into bus.";
// Set the filter coefficient to the whole file's duration; this will make
// the power monitor take the entire file into account.
media::AudioPowerMonitor power_monitor(wav_audio_handler->sample_rate(),
file_duration);
power_monitor.Scan(*audio_bus, audio_bus->frames());
// ...
return power_monitor.ReadCurrentPowerAndClip().first;
I wrote a new test, and hooked up the above logic instead of PESQ. I could compute Ain by running the above algorithm on the reference file (which I fed in using the flag I implemented above) and Aout on the recording of the output audio. At this point I pretty much thought I was done. I ran a WebRTC call with the AGC turned off, expecting to get zero… and got a huge number. Turns out I wasn’t done.
What Went Wrong?
I needed more debugging information to figure out what went wrong. Since the AGC was off, I would expect the power curves for output and input to be identical. All I had was the average audio power over the entire file, so I started plotting the audio power for each 10 millisecond segment instead to understand where the curves diverged. I could then plot the detected audio power over the time of the test. I started by plotting Adiff :
Figure 2. Plot of Adiff.
The difference is quite small in the beginning, but grows in amplitude over time. Interesting. I then plotted Aout and Ain next to each other:
Figure 3. Plot of Aout and Ain.
A-ha! The curves drift apart over time; the above shows about 10 seconds of time, and the drift is maybe 80 ms at the end. The more they drift apart, the bigger the diff becomes. Exasperated, I asked our audio engineers about the above. Had my fancy test found its first bug? No, as it turns out – it was by design.
Clock Drift and Packet Loss
Let me explain. As a part of WebRTC audio processing, we run a complex module called NetEq on the received audio stream. When sending audio over the Internet, there will inevitably be packet loss and clock drift. Packet losses always happen on the Internet, depending on the network path between sender and receiver. Clock drift happens because the sample clocks on the sending and receiving sound cards are not perfectly synced.
In this particular case, the problem was not packet loss since we have ideal network conditions (one machine, packets go over the machine’s loopback interface = zero packet loss). But how can we have clock drift? Well, recall the fake device I wrote earlier that reads a file? It never touches the sound card like when the sound comes from the mic, so it runs on the system clock. That clock will drift against the machine’s sound card clock, even when we are on the same machine.
NetEq uses clever algorithms to conceal clock drift and packet loss. Most commonly it applies time compression or stretching on the audio it plays out, which means it makes the audio a little shorter or longer when needed to compensate for the drift. We humans mostly don’t even notice that, whereas a drift left uncompensated would result in a depleted or flooded receiver buffer – very noticeable. Anyway, I digress. This drift of the recording vs. the reference file was natural and I would just have to deal with it.
Silence Splitting to the Rescue!
I could probably have solved this with math and postprocessing of the results (least squares maybe?), but I had another idea. The reference file happened to be comprised of five segments with small pauses between them. What if I made these pauses longer, split the files on the pauses and trimmed away all the silence? This would effectively align the start of each segment with its corresponding segment in the reference file.
Figure 4. Before silence splitting.
Figure 5. After silence splitting.
We would still have NetEQ drift, but as you can see its effects will not stack up towards the end, so if the segments are short enough we should be able to mitigate this problem.
Result
Here is the final test implementation:
base::FilePath reference_file =
test::GetReferenceFilesDir().Append(reference_filename);
base::FilePath recording = CreateTemporaryWaveFile();
ASSERT_NO_FATAL_FAILURE(SetupAndRecordAudioCall(
reference_file, recording, constraints,
base::TimeDelta::FromSeconds(30)));
base::ScopedTempDir split_ref_files;
ASSERT_TRUE(split_ref_files.CreateUniqueTempDir());
ASSERT_NO_FATAL_FAILURE(
SplitFileOnSilenceIntoDir(reference_file, split_ref_files.path()));
std::vector<:filepath> ref_segments =
ListWavFilesInDir(split_ref_files.path());
base::ScopedTempDir split_actual_files;
ASSERT_TRUE(split_actual_files.CreateUniqueTempDir());
ASSERT_NO_FATAL_FAILURE(
SplitFileOnSilenceIntoDir(recording, split_actual_files.path()));
// Keep the recording and split files if the analysis fails.
base::FilePath actual_files_dir = split_actual_files.Take();
std::vector<:filepath> actual_segments =
ListWavFilesInDir(actual_files_dir);
AnalyzeSegmentsAndPrintResult(
ref_segments, actual_segments, reference_file, perf_modifier);
DeleteFileUnlessTestFailed(recording, false);
DeleteFileUnlessTestFailed(actual_files_dir, true);
Where AnalyzeSegmentsAndPrintResult looks like this:
void AnalyzeSegmentsAndPrintResult(
const std::vector<:filepath>& ref_segments,
const std::vector<:filepath>& actual_segments,
const base::FilePath& reference_file,
const std::string& perf_modifier) {
ASSERT_GT(ref_segments.size(), 0u)
"Failed to split reference file on silence; sox is likely broken.";
ASSERT_EQ(ref_segments.size(), actual_segments.size())
"The recording did not result in the same number of audio segments "
"after on splitting on silence; WebRTC must have deformed the audio "
"too much.";
for (size_t i = 0; i float difference_in_decibel = AnalyzeOneSegment(ref_segments[i],
actual_segments[i],
i);
std::string trace_name = MakeTraceName(reference_file, i);
perf_test::PrintResult("agc_energy_diff", perf_modifier, trace_name,
difference_in_decibel, "dB", false);
}
}
The results look like this:
Figure 6. Average Adiff values for each segment on the y axis, Chromium revisions on the x axis.
We can clearly see the AGC applies about 6 dB of gain to the (relatively low-energy) audio file we feed in. The maximum amount of gain the digital AGC can apply is 12 dB, and 7 dB is the default, so in this case the AGC is pretty happy with the level of the input audio. If we run with the AGC turned off, we get the expected 0 dB of gain. The diff varies a bit per segment, since the segments are different in audio power.
Using this test, we can detect if the AGC accidentally gets turned off or malfunctions on windows, mac or linux. If that happens, the with_agc graph will drop from ~6 db to 0, and we’ll know something is up. Same thing if the amount of digital gain changes.
A more advanced version of this test would also look at the mic level the AGC sets. This mic level is currently ignored in the test, but it could take it into account by artificially amplifying the reference file when played through the fake device. We could also try throwing curveballs at the AGC, like abruptly raising the volume mid-test (as if the user leaned closer to the mic), and look at the gain for the segments to ensure it adapted correctly.