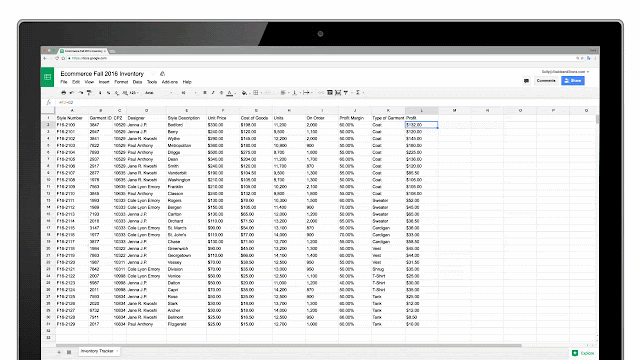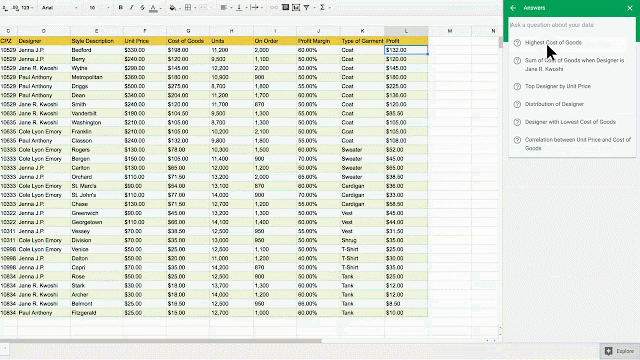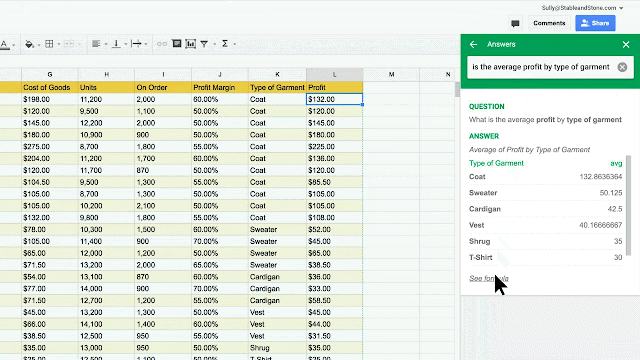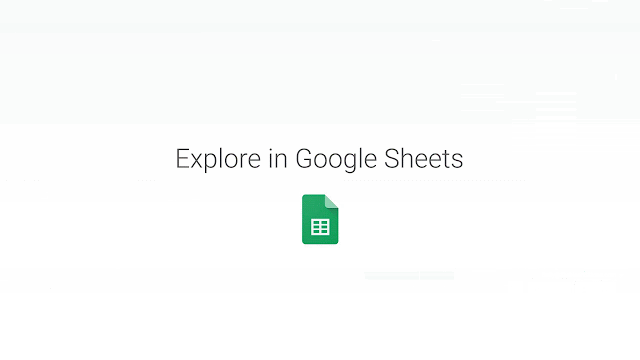
The ability to learn from experience will likely be a key in enabling robots to help with complex real-world tasks, from assisting the elderly with chores and daily activities, to helping us in offices and hospitals, to performing jobs that are too dangerous or unpleasant for people. However, if each robot must learn its full repertoire of skills for these tasks only from its own experience, it could take far too long to acquire a rich enough range of behaviors to be useful. Could we bridge this gap by making it possible for robots to collectively learn from each other’s experiences?
While machine learning algorithms have made great strides in natural language understanding and speech recognition, the kind of symbolic high-level reasoning that allows people to communicate complex concepts in words remains out of reach for machines. However, robots can instantaneously transmit their experience to other robots over the network - sometimes known as "cloud robotics" - and it is this ability that can let them learn from each other.
This is true even for seemingly simple low-level skills. Humans and animals excel at adaptive motor control that integrates their senses, reflexes, and muscles in a closely coordinated feedback loop. Robots still struggle with these basic skills in the real world, where the variability and complexity of the environment demands well-honed behaviors that are not easily fooled by distractors. If we enable robots to transmit their experiences to each other, could they learn to perform motion skills in close coordination with sensing in realistic environments?
We previously wrote about how multiple robots could pool their experiences to learn a grasping task. Here, we will discuss new experiments that we conducted to investigate three possible approaches for general-purpose skill learning across multiple robots: learning motion skills directly from experience, learning internal models of physics, and learning skills with human assistance. In all three cases, multiple robots shared their experiences to build a common model of the skill. The skills learned by the robots are still relatively simple -- pushing objects and opening doors -- but by learning such skills more quickly and efficiently through collective learning, robots might in the future acquire richer behavioral repertoires that could eventually make it possible for them to assist us in our daily lives.
Learning from raw experience with model-free reinforcement learning.
Perhaps one of the simplest ways for robots to teach each other is to pool information about their successes and failures in the world. Humans and animals acquire many skills by direct trial-and-error learning. During this kind of ‘model-free’ learning -- so called because there is no explicit model of the environment formed -- they explore variations on their existing behavior and then reinforce and exploit the variations that give bigger rewards. In combination with deep neural networks, model-free algorithms have recently proved to be surprisingly effective and have been key to successes with the Atari video game system and playing Go. Having multiple robots allows us to experiment with sharing experiences to speed up this kind of direct learning in the real world.
In these experiments we tasked robots with trying to move their arms to goal locations, or reaching to and opening a door. Each robot has a copy of a neural network that allows it to estimate the value of taking a given action in a given state. By querying this network, the robot can quickly decide what actions might be worth taking in the world. When a robot acts, we add noise to the actions it selects, so the resulting behavior is sometimes a bit better than previously observed, and sometimes a bit worse. This allows each robot to explore different ways of approaching a task. Records of the actions taken by the robots, their behaviors, and the final outcomes are sent back to a central server. The server collects the experiences from all of the robots and uses them to iteratively improve the neural network that estimates value for different states and actions. The model-free algorithms we employed look across both good and bad experiences and distill these into a new network that is better at understanding how action and success are related. Then, at regular intervals, each robot takes a copy of the updated network from the server and begins to act using the information in its new network. Given that this updated network is a bit better at estimating the true value of actions in the world, the robots will produce better behavior. This cycle can then be repeated to continue improving on the task. In the video below, a robot explores the door opening task.
Direct trial-and-error reinforcement learning is a great way to learn individual skills. However, humans and animals don’t learn exclusively by trial and error. We also build mental models about our environment and imagine how the world might change in response to our actions.
We can start with the simplest of physical interactions, and have our robots learn the basics of cause and effect from reflecting on their own experiences. In this experiment, we had the robots play with a wide variety of common household objects by randomly prodding and pushing them inside a tabletop bin. The robots again shared their experiences with each other and together built a single predictive model that attempted to forecast what the world might look like in response to their actions. This predictive model can make simple, if slightly blurry, forecasts about future camera images when provided with the current image and a possible sequence of actions that the robot might execute:

|
| Top row: robotic arms interacting with common household items. Bottom row: Predicted future camera images given an initial image and a sequence of actions. |

 |
 |
So far, we discussed how robots can learn entirely on their own. However, human guidance is important, not just for telling the robot what to do, but also for helping the robots along. We have a lot of intuition about how various manipulation skills can be performed, and it only seems natural that transferring this intuition to robots can help them learn these skills a lot faster. In the next experiment, we provided each robot with a different door, and guided each of them by hand to show how these doors can be opened. These demonstrations are encoded into a single combined strategy for all robots, called a policy. The policy is a deep neural network which converts camera images to robot actions, and is maintained on a central server. The following video shows the instructor demonstrating the door-opening skill to a robot:
Of course, the kinds of behaviors that robots today can learn are still quite limited. Even basic motion skills, such as picking up objects and opening doors, remain in the realm of cutting edge research. In all of these experiments, a human engineer is still needed to tell the robots what they should learn to do by specifying a detailed objective function. However, as algorithms improve and robots are deployed more widely, their ability to share and pool their experiences could be instrumental for enabling them to assist us in our daily lives.
The experiments on learning by trial-and-error were conducted by Shixiang (Shane) Gu and Ethan Holly from the Google Brain team, and Timothy Lillicrap from DeepMind. Work on learning predictive models was conducted by Chelsea Finn from the Google Brain team, and the research on learning from demonstration was conducted by Yevgen Chebotar, Ali Yahya, Adrian Li, and Mrinal Kalakrishnan from X. We would also like to acknowledge contributions by Peter Pastor, Gabriel Dulac-Arnold, and Jon Scholz. Articles about each of the experiments discussed in this blog post can be found below:
Deep Reinforcement Learning for Robotic Manipulation. Shixiang Gu, Ethan Holly, Timothy Lillicrap, Sergey Levine. [video]
Deep Visual Foresight for Planning Robot Motion. Chelsea Finn, Sergey Levine. [video] [data]
Collective Robot Reinforcement Learning with Distributed Asynchronous Guided Policy Search.
Ali Yahya, Adrian Li, Mrinal Kalakrishnan, Yevgen Chebotar, Sergey Levine. [video]
Path Integral Guided Policy Search. Yevgen Chebotar, Mrinal Kalakrishnan, Ali Yahya, Adrian Li, Stefan Schaal, Sergey Levine. [video]