Alexander Rehnborg works as SEO Specialist at Visma Spcs, a Google Analytics 360 customer, supplying over half of all small business owners in Sweden with accounting software.
Did you ever log on to Google Analytics to casually explore statistics, only to discover you’d missed out on important changes? As marketers we cannot afford to be “too late.”
Changes to consumer behavior, website performance and traffic trends often occur quickly without much notice. Still, a lot of marketers only explore their analytics data manually during certain days of the week or even month. Imagine your important AdWords campaign or product page suddenly taking off, and you’re not in the control room to react?
With that in mind, I will discuss six vital areas you should monitor automatically with what I believe to be a the vastly underused feature in Google Analytics: “Custom Alerts.” If you didn’t read yet, check out last week’s announcement on the home of Custom Alerts.
Automated and Custom Alerts
Luckily, Google Analytics offers several features to monitor important data changes and alert you instantly. Two of the most important features are Custom Alerts and Automated Insights. The latter is a newly introduced part of the GA Assistant app for Android and iOS, using machine learning to discover critical insights among your data and alert you instantly.
In addition to the automated insights, you have the ability to set up your own custom alerts according to the KPIs you’re especially interested in, and be alerted by both email and sms. Once you receive the alerts, you may click on the link for the report to be taken straight into a dashboard, only displaying the metrics changes you’ve been alerted about.
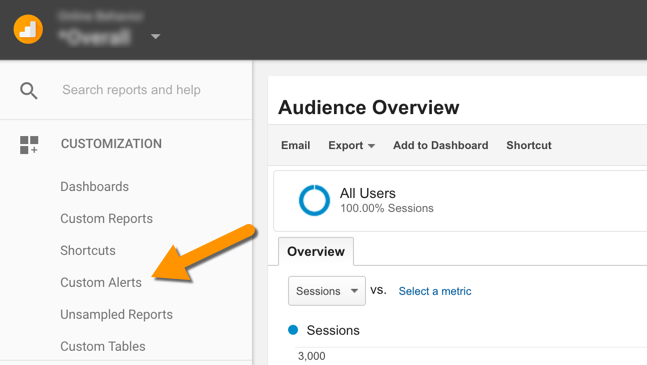
This gives you complete focus on quickly understanding what has contributed to the change in data. You will find the Custom Alerts under the customization tab in the left sidebar of the View you want to monitor (see screenshot below).
You will find Custom Alerts under the Customization tab in the left sidebar.
6 Custom Alert Areas You Shouldn’t Miss
The scope and magnitude of the data change you’re monitoring will vary according to each business. Therefore it’s important to continuously refine the alerts guided by the common data movements you’ve seen historically for your site. Let’s start out with the six basic areas of metrics we want to monitor, inspired by LunaMetrics’ excellent guide.
1. Emergency
This is one of the main reasons you want to monitor your data in the first place – if something goes wrong, you want to know as soon as possible. Since the quickest alert you may receive is being sent daily, it’s recommended to pay extra attention to the Automated Insights function inside the Google Analytics Assistant app. Each of these alerts will be set to a daily time period.
Average Page Load time > 10 seconds Today
Be sure to set a couple of these alerts, one for the entire site and one for each page critical to your business. Slow load times not only affect engagement and conversion, it may affect your organic search ranking as well. Regular problems with load time may point to technical problems that should be addressed. Unsure of how well your site is performing today? Use Google’s PageSpeed Insights.
No Sessions Today
If this alert goes off, you’ll probably have some investigative work to do.
No Conversion / Goal X Today
If you’re running an e-commerce platform, this value might be a purchase, trial or demo download. For businesses offering services, no events triggered by contact forms may be the most important conversion metric. Whatever your key conversion KPIs are and depending on how often conversions normally occur, you want to monitor this daily or weekly.
2. Performance
Monitoring the performance of your site is like having a doctor constantly checking up on your health. Even though irregularities occur naturally, many sites suffer from poor server performance, cluttered or poorly written web code and other factors directly affecting your business online. These alerts you may set to weekly or monthly, depending on your traffic and needs. For every alert about an increase, you also need one for a decrease.
> 10% Increase / Decrease in Average Page Load Time Compared to Last Month
A monthly check-up here is just what every site needs. It’s recommended to manually look for the top-5 or top-10 pages on your site with the slowest load time, and adding these under a custom alert for special monitoring.
> 10% Increase / Decrease in Average Redirection Time Compared to Last Month
Especially larger businesses that perform redirects regularly ought to make sure these do not slow down the response time for the visitor. Some web servers don’t handle larger volumes of redirects all too well.
> 10% Increase / Decrease in Average Server Response Time Compared to Last Month
More businesses should demand high performance from their web servers. Especially small businesses often make the mistake of purchasing web space from providers that underperform.
> 10% Increase / Decrease in Page Download Time Compared to Last Month
This is a useful alert for the entire site when working with content marketing. When working in a large team of editors, it’s not unusual to discover unnecessarily large images embedded into pages, effectively prolonging the page download time.
3. Traffic
Without it, your online business dies out. Monitoring traffic is essential to develop your content marketing efforts and understand which parts of your site are really delivering as you expect. Alerts set to a weekly time period should work out fine.
> 10 Non-Domain Sessions Today
Possibly not alarming, but if you’re receiving sessions from unknown/unidentified domains, you may be target of spam. Apply the value “(not set)” with regex to Hostname.
> 10% Increase / Decrease in Content Sessions Compared to Last Week
Weekly monitoring for sites focusing on content marketing, volumes might vary between businesses. If you’ve got several URL paths with content, you may use regex to define those paths, such as “content-a|content-b|content/small-business”.
> 20% More / Fewer New Sessions Compared to Last Week
This gives you insight into the nature of your traffic over time. If you ran a PR campaign the previous week, did you manage to deliver a great portion of new sessions?
> 20% Increase / Decrease in AdWords Clicks / Cost / CPC / CTR / Impressions Compared to Last Week
Your search engine marketing professional will love these automatic alerts, giving you weekly feedback on the paid search traffic and which campaigns contribute to any significant changes.
4. Engagement
Your focus here may lie entirely on classic metrics for user engagement, or you may add a mix of social media metrics to measure your efforts in those channels. Both daily and weekly alert periods make sense here.
> 5 Social Shares Today
This will vary according to your business, but following social shares of your content from your site ought to be a part of all content marketing reporting.
> 10% Increased / Decreased Bounce Rate Compared to Last Week
This debated but still interesting metric may point to engagement improvements or issues, especially if applied to specific landing pages with individual alerts.
> 20% Shorter / Longer Average Session Duration Compared to Last Week
Like with bounce rate, this may or may not point to deeper improvements or issues with user engagement. Clicking on the report link from the alert will highlight which pages contributed to the change.
5. Conversion
If you’re running a larger e-commerce website, you’ll want to measure a lot more than just a general conversion rate. You may experiment with alerts for average order value (AOV), revenue and pure number of transactions. Because metrics like AOV may change a lot depending on your product offerings online and sales trends, you may want to choose monthly alerts summarizing broader changes.
> 10% Increase / Decrease in Conversion Rate Compared to Last Week
Depending on how many conversion goals you’ve got set up, this may point to an overall conversion rate, or consist of several individual alerts for all your important conversion goals.
6. Settings
Some traffic changes are simply down to how it’s attributed. Keep a watching eye on these and related metrics.
> 20% Increase in Not Set AdWords Keywords Compared to Last Week
Here you use the value “(not set)” with exact match for Keyword. If you’re alerted about this, you need to talk to your search marketing professional to make sure all campaigns are correctly set up.
> 100 Sessions Missing Campaign Parameters Last Week
Even though it may be difficult, it’s never ideal to run ad campaigns without tagging the campaign links correctly. The volume and time period will vary between businesses, but a suggestion is to apply the value “(not set)” with regex to Medium. From here on you may dive deeper to discover unattributed traffic.
Closing Thoughts
It doesn’t matter if you’re a Google Analytics professional with years of experience or a beginner currently attending the Google Analytics Academy. Automatic monitoring of your analytics data is an essential part of digital marketing today. Over time you may find that it’s more effective to be alerted about actual changes, rather than “looking” for them. With that said, when alerted you need to do what you’ve always done, which is to manually explore the data in detail and dig out the insights.
Posted by Daniel Waisberg and Valentina Borovaya, Google Analytics team