Online Machine Learning Testing == Extreme Testing
November 25th, 2008 | Published in Google Testing
- Is this email spam?
- Is this search result relevant?
- What product category does that query belong to?
- What is the ad that users are most likely to click on for the query “flowers”?
- Is this click fraudulent?
- Is this ad likely to result in a purchase (not merely a click)?
- Is this image pornographic?
- Does this page contain malware? –Should this query bring up a maps onebox?
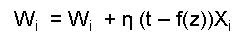
Where X is the set of input values of Xi ,W is set of the importance factors(weights) of every value Xi. A positive weight means that that risk factor increases the probability of the outcome, while a negative weight means that that risk factor decreases the probability of that outcome. t is the target output value, η is the learning rate(the role of the learning rate is to control the level to which the weights are modified at every iteration and f(z) is the output generated by the function that maps large input domain to a small set of output values in this case. The function f(z) in this case is the logistic function:

z = x0w0 + x1w1 + x2w2 + ... + xkwk
The logistic function has nice characteristics since it can take any input, and basically squash it to 0 or 1. Ideal for predicting probabilities on events that are dependent on multiple factors(Xi) each with different importance weights(Wi). The Stochastic Gradient Descent provides fast convergence to find the optimal minimums of the error(E) that the function is making on the prediction as well as if there are multiple local minimums the algorithms guarantees converging to the global minimum of the prediction error. So let’s go back now into the real online world where we want to give answers (predictions) to our users in milliseconds and ask the question how are we going to design automated tests for the Stochastic Gradient Descent Algorithm embedded into a live online prediction system. The environment is pretty agile and dynamic, the code is being changed every hour, you want your tests to run on 24/7 basis, you want to detect errors upstream in the development process, but you don’t want to block the development process with tests that are running days, on the other side you want to release new features fast, but the release process has to be error prone(imagine the world with google being down for 5 mins, that is a global catastrophe, isn’t it?!
So let’s look at some of the test strategies:
Should we try to train the model(set of the importance factors) and test the model with the subset of the training data? What if this takes far more than hours, maybe days to do that? Should we try to reduce the set of importance factors (Xi) and get the convergence(E->0) on the reduced model?
Should we try to reduce the training data set(the variety of set of values for X as an input to the algorithm) and keep the original model and get the convergence by any price? Should we be happy with reducing both the model size and the training set? Are we going to worry for over-fitting in the test environment? Given the original data is online data and evolves fast, are we going to be satisfied with fixed data test set or change the input test data frequently? What are the triggers that will make you do so? What else should we do?
Drop us a note, all ideas are more than welcome.