Ngram Viewer 2.0
October 18th, 2012 | Published in Google Books, Google Research
Since launching the Google Books Ngram Viewer, we’ve been overjoyed by the public reception. Co-creator Will Brockman and I hoped that the ability to track the usage of phrases across time would be of interest to professional linguists, historians, and bibliophiles. What we didn’t expect was its popularity among casual users. Since the launch in 2010, the Ngram Viewer has been used about 50 times every minute to explore how phrases have been used in books spanning the centuries. That’s over 45 million graphs created, each one a glimpse into the history of the written word. For instance, comparing flapper, hippie, and yuppie, you can see when each word peaked:

Meanwhile, Google Books reached a milestone, having scanned 20 million books. That’s approximately one-seventh of all the books published since Gutenberg invented the printing press. We’ve updated the Ngram Viewer datasets to include a lot of those new books we’ve scanned, as well as improvements our engineers made in OCR and in hammering out inconsistencies between library and publisher metadata. (We’ve kept the old dataset around for scientists pursuing empirical, replicable language experiments such as the ones Jean-Baptiste Michel and Erez Lieberman Aiden conducted for our Science paper.)
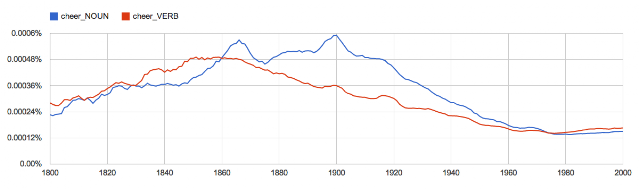
At Google, we’re also trying to understand the meaning behind what people write, and to do that it helps to understand grammar. Last summer Slav Petrov of Google’s Natural Language Processing group and his intern Yuri Lin (who’s since joined Google full-time) built a system that identified parts of speech—nouns, adverbs, conjunctions and so forth—for all of the words in the millions of Ngram Viewer books. Now, for instance, you can compare the verb and noun forms of “cheer” to see how the frequencies have converged over time:

Oh, and we added Italian too, supplementing our current languages: English, Chinese, Spanish, French, German, Hebrew, and Russian. Buon divertimento!